Dynamic Fusion Network for Multi-Domain End-to-end Task-Oriented Dialog
中文标题:面向多领域端到端的任务型对话系统的动态融合网络 这篇papar发表在ACL2020会议上,是哈工大SCIR(在中国,NLP的很顶尖的实验室)一作的文章。
第一遍粗读
粗读:浏览论文的结构和各个标题,之后看摘要(Abstract)和结论(Conclusion)。
论文结构:
粗读之后的问题:
- shared-private network是个什么样的网络?
- Dynamic Fusion Network又是一个什么样的网络?它是如何自动探索目标领域和每个领域的相关性的?
- 论文提出的模型如何只用少量标注数据快速适应到新领域的?
- "Seq2Seq对话生成"具体是什么样的?
- 知识查询?动态融合?
- 论文里的对抗训练是什么样的?
- Baseline里面的那几个模型又是什么样的?对比的各个评价指标是什么?
- 什么是消融?提前放个链接
第二遍精度论文中给出的图、表
Figure 1

下半张图是一个任务型对话,对话关联了上半张图所示的来自SMD数据集的knowledge base(KB, 知识库)。对话里是司机(Driver)和车(Car),其中相同颜色的词代表查询到的knowledge base中的实体(entity)。
SMD数据集: Stanford Multi-Domain Dialogue Dataset---一个包含3031个多回合对话的语料库,对话属于车内助手的三个不同领域:日历调度、天气信息检索和兴趣点导航。 参考链接 POI: Point-of-Interest---兴趣点(在上面的图中POI是指地址处的兴趣点:机构或者地点名或者店名等等)
Figure 2
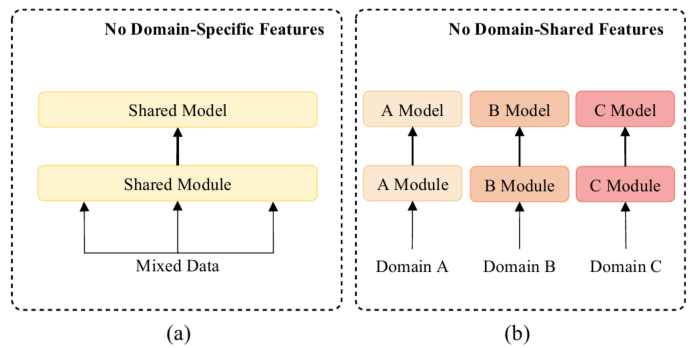
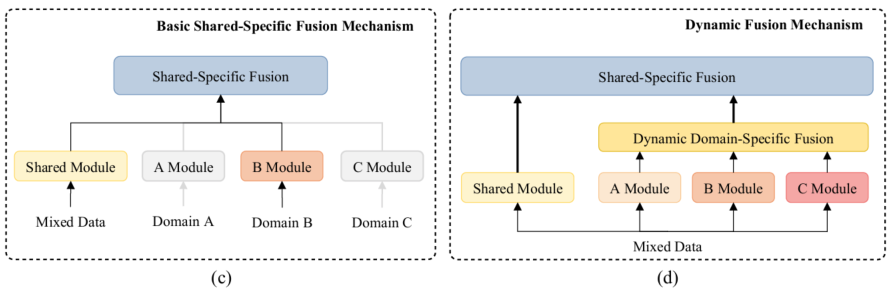
上面的图片有关多领域对话的方法。在之前的工作中要么在混合的多领域的混合数据集训练一个统一的模型(a图),要不就是在分开在各个领域训练(b图)。基础的shared-private框架如图c所示,作者提出包含动态融合机制的拓展如图d所示。
问题: 1. 图d中A Module、B Module、C Module各自的区别是什么?它们又跟Shared Module有什么区别?
Figure 3
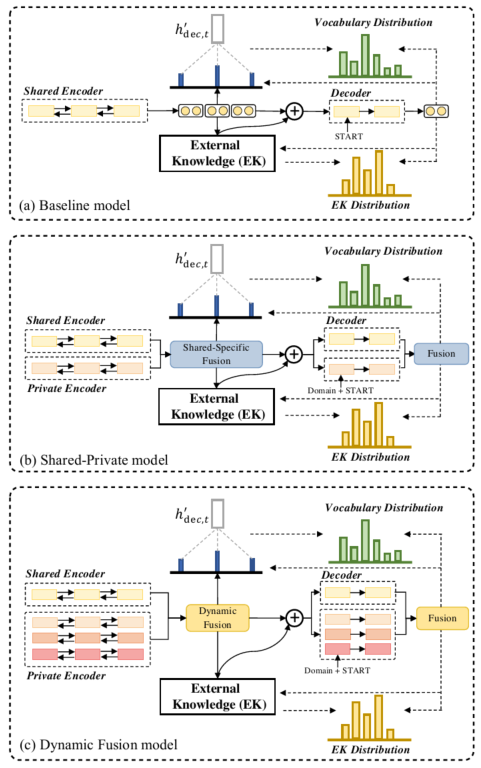
上面的图片展示的是baseline模型和作者提出的模型的工作流程。
问题: 1. 整个的流程具体什么样的?
Figure 4
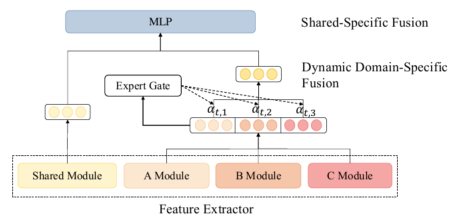
融合domain-shared(“领域共享”)特征和domain-specific(“领域特定”)特征的动态融合层。
问题: 1. domain-shared和domain-specific特征是不同领域共享特征和各个领域里特定特征的区别吗?
- 融合方式是什么?
其他性能图表和图片
最后精度的时候分析。
第三遍精读全文
摘要(Abstract)
近期的端到端任务型对话系统研究已经取得巨大的成功。可是,绝大多数的神经模型依赖大量训练数据,而大量的训练数据仅仅特定几个任务领域(例如:导航和schedule)拥有。上述情况就让只具备有限数据的新领域扩展比较困难,但是已经有一些关于如何使用所有领域的数据去提高其中每个领域和全新领域的性能的相关的研究。为了上述目的,作者研究了能够直接使用领域知识的方法并引入shared-private网络去学习共享的知识和特定的知识。另外,作者提出一个新的动态融合网络,它能够自动探索目标领域和每个领域的相关性。结果显示作者的模型比现在已有的多领域对话模型效果更好。除此之外,在只有少量数据的情况下,作者提出的模型比之前最好模型的通用性(可转移性)平均要好13.9%。
引言(Introduction)
任务型的对话系统帮助用户去实现特定的目标,例如餐馆预约或者导航。近年来,端到端的方法通常使用序列到序列(sequence-to-sequence)模型依旧对话历史去生成回应。如图1中的对话,为了回答司机关于“加油站”的询问,在给定了询问和一个相应知识库时端到端的对话系统直接生成系统回复。
尽管实现了比较好的性能,但是端到端模型依靠大量的标签数据,这就限制了端到端模型在新领域或者扩展领域的使用。实际上,我们无法收集到每个新领域的大量数据。所以,研究能够有效地将知识从一个有丰富标签数据的领域转移到一个只有很少的标签数据的领域很重要。
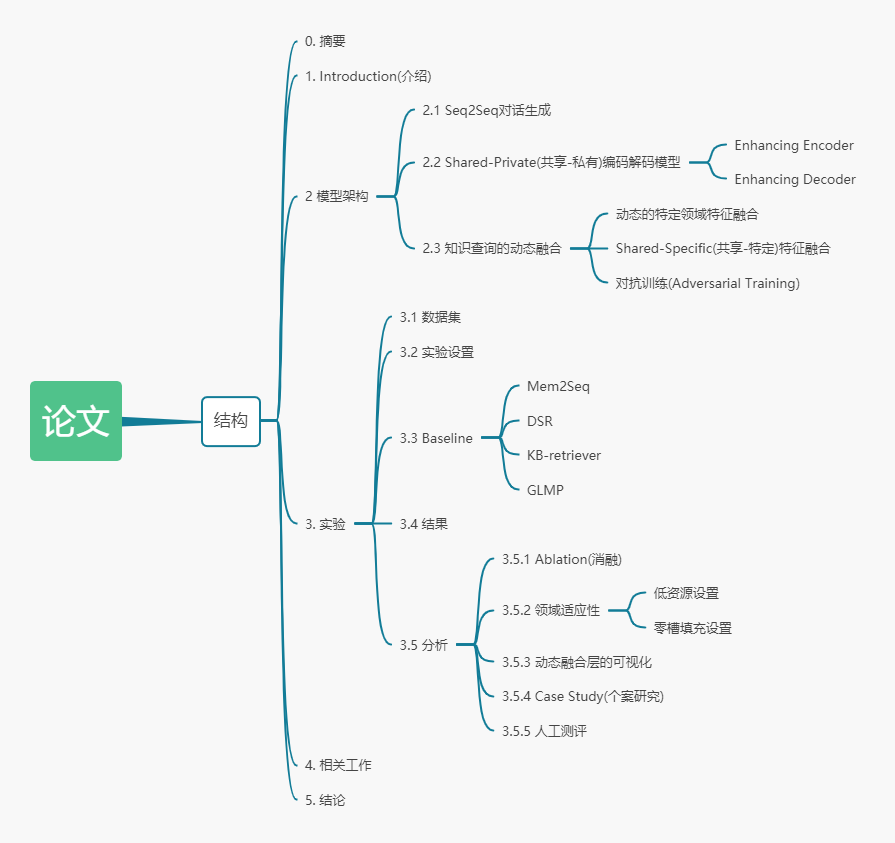
现有的工作可以被分为两个主要类别。如图2(a)所示,第一种是简单地整合整合多领域数据集进行训练。这种方法能够(隐式地)提取到共同特征但是无法有效获取领域特定的知识。如图2(b)所示,第二种方法是分别训练每个领域的模型,这样能够更好地提取到领域特定的特征,然而,这样就忽略了不同领域之间的共享知识(例如,"位置"同时存在于schedule和导航)。
作者考虑通过显示建模领域之间的知识关联解决现有工作的的局限,一个结合了领域间共享特征和领域私有特征的简单的baseline是shared-private框架。如图2(c)所示,它包含了一个共享模型去提取共享特征还有每个领域的私有模块。这种方法明确区分了共享知识和私有知识。然而,这个框架仍然存在两个问题:(1) 给定一个只有极少数据的新领域,它对应的私有模块无法有效提取相关领域的知识。(2)它忽略了领域的特定子集之间的细粒度相关性(例如:与天气领域相比,schedule领域和导航更相关)。
为了解决上述问题,作者进一步提出了一个全新的动态融合网络,如图2(d)所示,与shared-private模型相比,动态融合模块(在2.3小节)进一步明确捕获到领域之间的相关性,尤其是其中利用的自动找到当前输入和所有领域特定的模型的相关性的门(gate),所以为了提取知识给每个领域赋上了一个权重。编码器(encoder)和解码器(decoder)都使用这样的机制,以及一个能够查询知识库特征的记忆模块。给定一个少量训练数据或者没有训练数据的新领域,作者的模型仍然最好地利用了现有的领域,这是baseline模型无法做到的。
作者在两个公共标准数据集(SMD和MultiWOZ)上做了实验。结果显示作者的模型始终能够很大地超越当前最好的方法。在只有少量数据的情况下,作者提出的模型比之前最好模型平均要好13.9%。
据作者所知,这是第一个能够有效在多领域端到端任务型对话中拓展shared-private架构。另外,给定一个少量训练数据或者没有训练数据的新领域,拓展的动态融合框架可以利用细粒度的知识来获得预期的准确度,这就让模型能够对新领域很友好。
2 模型架构(Model Architecture)
作者基于Seq2Seq对话生成模型构建了自己的模型,如图3(a)所示。为了明确整合领域知识,如图3(b)所示,作者第一次提出了使用一个shared-private框架(在第2.2节)去学习共享特征和领域特定的特征。接下来,为了细粒度知识转移(knowledge transfer),作者进一步使用了一个动态融合网络去动态挖掘所有领域的相关性,如图3(c)所示。另外,为了促进共享模块生成领域共享特征而使用了对抗训练。
2.1 Seq2Seq对话生成
作者将Seq2Seq任务型对话生成定义为根据输入对话历史\(X\)和知识库(KB) \(B\)找到的系统回应\(Y\)。一个回应(response)的概率被定义为: 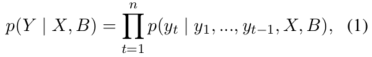
其中,\(y_t\)代表输出里的一个token。在Eric等人的Seq2Seq任务型对话系统中采用LSTM(长短时记忆)网络来编码对话历史\(X = (x_1, x_2,\cdots, x_T)\) (\(T\)代表对话历史的token数)以生成共享的上下文敏感的隐藏状态\(H = (h_1, h_2, \cdots, h_T)\): 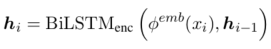
其中,\(\phi_{emb}(\cdot)\) 代表词向量矩阵。LSTM被解码器隐藏状态 \((h_{dec,1}, h_{dec,2}, \cdots, h_{dec_t})\) 反复用于预测输出 \((y_1, y_2, \cdots, y_{t-1})\) 。为了生成 \(y_t\) ,模型首先计算了一个对话历史关于编码中\(H\)的attentive(注意力)代表 \(\hat{h_{dec,t}}\) ,然后 \(h_{dec,t}\) 和 \(\hat{h_{dec,t}}\) 串联起来通过矩阵\(U\)映射到词空间\(V\): 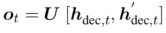
其中,\(o_t\)是为生成下一个token的分数。下一个token \(y_t \in V\)的概率为: 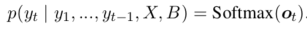
不同于典型的Seq2Seq模型的文本生成,任务型对话系统中的成功的对话十分依赖知识库(KB)查询的准确性。我们采用全局到局部的记忆指针机制(GLMP)去查询KB中的实体,它拥有最好的性能。作者还提出了一个储存知识库\(B\)和对话历史\(X\)的外部知识记忆。知识库(KB)被设计为充作知识源,同时对话被用作直接复制历史词(history words)。在外部知识中的实体被表示为一个三元组,存储在记忆模块(memory module),记忆模块可以表示为\(M = [B;X] = (m_1, \cdots, m_{b+T})\) , \(m_i\) 是 \(M\) 其中的一个三元组,\(b\) 和 \(T\)分别代表知识库(KB)和对话历史的数量。对于一个k跳记忆网络,外部知识由可训练的embedding矩阵\(C = (C^1, \cdots, C^{k+1})\)集合组成。我们可以利用知识模块在编码及解码的过程进行知识库查询去加强模型的相互作用。
编码器中的知识查询 作者采用了最后一个隐藏状态作为初始的查询向量: \[ q_{enc}^1 = h_T (Eq.5) \]
另外,可以通过k跳循环并计算每k跳的注意力权重: 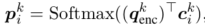
其中, \(c_{i}^k\) 是向量矩阵 \(C^k\) 中第i个memory位置的向量。作者使用全局记忆指针 \(G = (g_1, \cdots, g_{b+T})\) ,其中 \(g_{i}^{k} = Sigmoid((q_{enc}^{\top}))\) ,这个用来解码时过滤外部知识的相关信息。
最后,模型根据加权后的 \(c^{k+1}\) 的和读取memory \(o^{k}\) 并更新查询向量 \(q_{emc}^{k+1}\) : 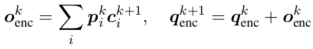 \(q_{enc}^{k+1}\) 可以被看做是编码后的知识库信息,并被用于初始化解码器。
\(q_{enc}^{k+1}\) 可以被看做是编码后的知识库信息,并被用于初始化解码器。
解码器中的知识查询 作者采用了一个sketch标记(以特殊token开头)去表示所有可能的槽类型(例如:'@address'代表所有的\(Address\)(地址))。一个sketch标记在时间步长t生成(通过Eq.4)后,使用隐藏状态 \(h_{dec,t}\) 和注意力(attentive) \(\hat{h_{dec,t}}\) 的串联去访问知识,这个和在编码器中查询知识的过程很像: 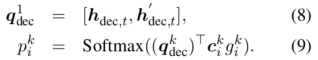
在这里可以将\(P_t=(p_{1}^{k}, \cdots, p_{b+T}^{k})\)当作被查询到的知识的概率,然后从查询结果中选择拥有最高的概率的词作为生成的词。
GLMP:GLMP 是基于 Mem2Seq 的改进,整体框架基于 MemNN,包含 encoder 和 decoder,encoder 编码对话历史,输出全局记忆指针和全局上下文表示。decoder 提出 sketch RNN,先产生 sketch(草稿) 的未填充 slot(槽位) 的响应,再根据全局记忆指针过滤外部知识库查找信息,最后用局部记忆指针实例化未填充的 slot。
1-hop:对邻居结点的聚合;k-hop:当网络加深到k层的时候聚合关系扩充到k跳。
2.2 Shared-Private 编码解码模型
在2.1小节的模型是在混合的多领域数据集上训练的,模型参数在所有领域都是共享的,我们把这样的模型叫做shared encoder-decoder模型。在这里,我们提出使用shared-private框架,它包含一个为了提取领域共同特征的共享编码器-解码器(shared encoder-decoder)和一个为了提取不同领域特定的特征的私有模型。每个实例\(X\)需要经过shared encoder-decoder和它(所在领域)对应的private encoder-decoder。
加强编码器(Enhancing Encoder) 给定一个实例和它的领域,shared-private encoder-decoder生成一个编码器向量的序列(表示为 \(H_{enc}^{\{s,d\}}\) ),它包含来自相应编码器的共享表示和领域特定表示: 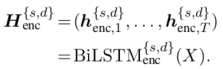
最后的shared-specific编码表示\(H_{enc}^{f}\)是混合起来的: 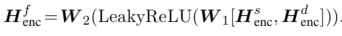
为了便于说明,作者将shared-specific融合函数定义为: 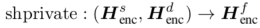
另外,自注意力在获取上下文信息很有用,最后作者也对 \(H_{enc}^{f}\) 采用自注意力来获取上下文向量 \(c_{enc}^{f}\)。在公式5(Eq.5)中将 \(h_{T}\) 替换为 \(c_{enc}^{f}\) (如下所示),这就让查询向量结合了领域共同特征(domain-shared feature)和领域特定特征(domain-private feature)。 \[ q_{enc}^1 = c_{enc}^{f} \]
加强解码器(Enhancing Decoder) 在解码器的(t step)第t步时,私有和共享隐藏状态为: 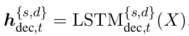
作者同样在这里的隐藏状态应用了shared-specific融合函数,混合后的向量: 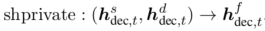
同样的,通过 \(H_{dec,t}^{f}\) 求出 \(h_{dec,t}^{f}\) 的注意力便得到了融合注意力 \(h_{dec,t}^{f^\prime}\) 。最后将公式8(Eq.8)中的 \([h_{dec,t},h_{dec,t}^\prime]\) 替换为 \(h_{dec,t}^{f},h_{dec,t}^{f^\prime}\)。
2.3 知识查询的动态融合
shared-private框架能够捕捉到相应的特定的特征,但是忽略了各领域领域子集合之间的细粒度相关性。作者进一步提出了动态融合层去显示利用所有领域的知识,如图4所示。给定一个任意领域的实例,首先将它放到多个private encoder-decoder中,这样是为了获取领域特定(domain-specific)的特征。接下来,所有的领域特定(domain-specific)的特征被一个动态的domain-specific特征融合模块融合,后面就是为获取shared-specific特征的融合。
动态Domain-Specific特征融合 给定来自各个领域的domain-specific特征,在编码器和解码器中为当前输入采用一个Mixture-of-Experts机制(MoE)动态合并所有的domain-specific知识。现在来详细描述一下如何融合timestep \(t\)的decoding,融合过程和encoder的是一致的。给定全部领域在t时刻decoding时的特征表示 \(\{h_{dec,t}^{d_i}\}^{D} _ {i=1}\) ,其中 \(D\) 代表领域的数量。模型中有一个专家门(expert gate) \(E\) ,它将 \(\{h_{dec,t}^{d_i}\}\)作为输入,输出一个softmax值 \(\alpha_{t,i}\) ,\(\alpha_{t,i}\)代表每个领域和当前输入token的相关程度,该专家门是通过一个简单的前向传播层实现的: 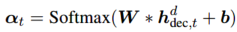
最后的领域特定特征向量是所有领域输出组成的矩阵,然后乘上expert gate输出的分数,最后为: 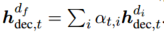
在训练期间,以解码器为例,专家门(expert gate)以交叉熵损失 \(L_{dec}^{moe}\) 作为监督信号来预测响应中每个token的领域。在multiple private解码器中,专家门的输出 \(\alpha_{t}\)可以视为预测的 \(t^{th}\)token的所属领域的概率分布。所以,领域预测越准确,专家门越正确: 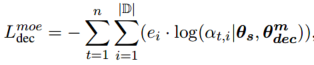
其中,\(\theta_{s}\)代表encoder-decoder模型的参数, \(\theta_{dec}^{m}\)代表decoder中MoE模块(Eq.15)的的参数,\(e_i \in \{0,1\}\) 代表 \(n\) tokens是否属于 \(d_i\)领域,相似地可以得出编码器的交叉熵损失 \(L_{enc}^{moe}\),所以它们一起表示为: \(L_{moe} = L_{enc}^{moe}+L_{dec}^{moe}\) .
\(L_{moe}\) 能够有助于来自一个特定源领域的样本使用正确的expert(专家),同时每个专家学习到相应的特定领域特征。专家门能够自动计算一个拥有很少或者没有标签数据的新领域和已有领域之间的相关性,这样就能更好地在编码器和解码器中传递不同源领域之间的知识。
Shared-Specific特征融合 作者直接应用shaprivate操作去融合共享特征和最后的特定领域特征: 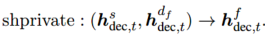
最后,作者将动态融合函数表示为动态\((h_{dec,t}^{s},\{h_{dec,t}^{d_f}\}^{D} _ {i=1})\)。和2.2节一样,作者将Eq.8公式中的 \([h_{dec,t}, h_{dec,t}^\prime]\)替换为\([h_{dec,t}^f, h_{dec,t}^f\prime]\),其余的配置和shared-private encoder-decoder框架一样。
对抗训练(Adversarial Training) 为了促进模型学习领域共享特征,作者在编码器和解码器应用了对抗式学习。学习 Liu et al.(2017)等人的方式,在领域分类层后面加入了梯度反转层(gradient reversal layer)。对抗式训练的损失表示为\(L_{adv}\),作者学习Qin et al.(2019a),将动态融合网络最后的损失函数定义为: 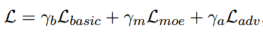
其中,\(L_{basic}\)和GLMP模型一致,\(\gamma_b\) , \(\gamma_m\)以及 \(\gamma_a\)是超参数。(具体的关于\(L_{basic}\)和\(L_{adv}\)信息,参考论文附录)
论文中的实验及效果等等参考论文。
结论
在这篇文章,作者提出使用一个shared-private模型去研究多领域对话的领域知识的显示建模。另外,动态融合层是为了动态地捕捉目标领域和所有其他源领域相关性而提出的。在两个数据集上的实验展示了所提出模型的有效性。除了上述内容,作者的模型能够很快地适应到一个标注数据较少的新领域。
回答提出的问题
shared-private network是个什么样的网络? / Dynamic Fusion Network又是一个什么样的网络?它是如何自动探索目标领域和每个领域的相关性的?
- 直接用对比图来回答(shared-private network是个什么样的网络? and Dynamic Fusion Network又是一个什么样的网络?):
key point for me:参考ConcLab中的e2e模型:Sequicity中的model里面的reinforce优化(rl),能否使用?
key point for me:在非端到端式的对话系统的强化学习的Policy中有个
Policy Gradient Methods,是否可以让它和gradient reversal layer相结合?(为了对抗式学习) 已知CrossWOZ已经有了Dialogue Policy Learning的benchmark:SL plicy(from ConcLab-2)的Dialogue act F1。
key point for me : 1.\(g_{i}^{k}\)用tanh?会怎么样? 2.BiLSTM做encoder、LSTM做decoder,是否需要换成GRU?为了减少计算资源(LSTM比起GRU结构复杂,所需的计算资源大,但是效果往往比GRU好。) 3.用
Transformer架构替换BiLSTM-LSTM的encoder-decoder? 并且参考京东AI research的《Self-Attention Guided Copy Mechanism for Abstractive Summarization》中的centrality score(通过最后一层encoder的self-attention分数,计算每个token节点的重要性分数。)