小样本学习(Few-shot Learning)
1 什么是小样本学习(Few-shot Learning)?
对于人类来说,我们可以通过极少量的样本来认识一个新物体,比如通过几张图片就能认识火龙果和牛油果,并能对他们进行很好的区分。但是对于机器来说,传统的深度神经网络需要很多很多的图片(或者说数据)才能很好的学习到一个新物体的特征并进行不同物体的分类。
那么,机器学习模型在学习了一定类别的大量数据后,对于新的类别,只需要少量的样本就能快速学习,这就是小样本学习(Few-shot Learning)要达到的目标。Few-shot Learning是一种思想,它其实并不指代某种具体的算法或者模型,这种思想可以应用到很多场景,比如分类(classification),这时候便是Few-shot Classification。因为大部分都是将Few-shot Learning用在了分类上,所以一般它就直接代表Few-shot Classification。
2 N-way k-shot问题
通常,Few-shot Learning被描述为N-way k-shot问题,也就是:
- 已有一定量的标注数据,数据中包含多个类别,但每个类别的数量不多。将这些数据称为train set(训练集)。用train set通过某种方法得到一个模型\(M\)。
- 给定一个新的标注数据,有\(N\)个类,每类中有\(k\)个样本,称之为support set(支持集)。support set中的类别和train set中的类别不存在交叉(不相同)。
- 通过借助support set但不修改模型\(M\)的参数,使之能在给定一个新的输入时能将其识别为\(N\)个类中的一个。
这就是N-way k-shot问题。k的取值一般较小(10以下),当k=1时该问题也称为one-shot,当k=0时称之为zero-shot。
模型\(M\)拥有的两大能力:
- 将一个类别的数据表示为一个向量,作为这个类的representation(表示)。
- 将一个输入和一个类的representation进行比较,判断两者的相似程度(匹配程度)。
模型\(M\)的第1个能力使其能够处理任意新的类别。不管给什么样的support set,总能产生\(N\)个向量来表示其中的\(N\)个类别。最简单的办法是:首先用train set进行表示representation的学习(为了得到各个样本的向量),然后对给定的support set,将其中每个类的k个样本的向量进行加和或者平均作为类的表示representation。在预测的时候,对预测的数据同样进行向量化表示,然后和这些类的表示representation计算相似性(距离),选择距离最小的类最为预测结果。
为了尽量和实际使用时接近,上述的few-shot classification(少样本分类)在训练时引入一个叫做episode的概念,每个episode包含从train set中采样出来的一部分数据以及用这部分数据进行训练的过程。具体来说episode的过程如下: 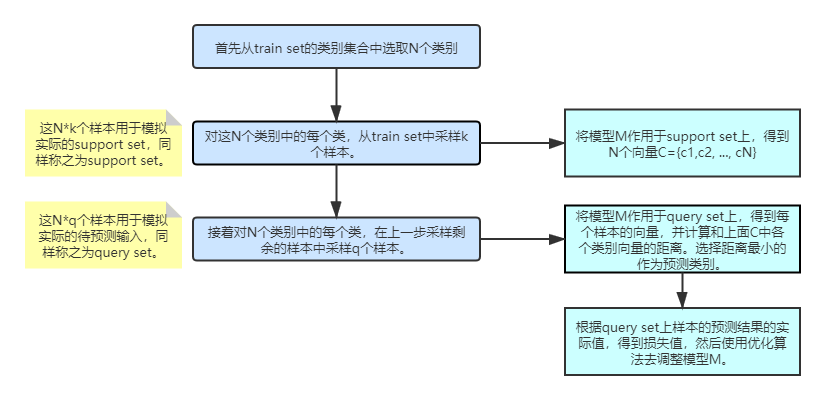
meta learning:learning to learn(学习如何去学习)。推荐:李宏毅老师的深度学习视频(里面有meta-learning)b站上的视频传送门