XGBoost
1 XGBoost
1.1 什么是XGBoost?
XGBoost:eXtreme Gradient Boosting,从名字上我们知道它是在梯度提升Gradient Boosting框架下的集成学习算法。
XGBoost是之前博客所讲的GBDT(传送门)的高效实现。XGBoost中的基学习器可以是CART决策树,也可以是线性分类器。我们说XGBoost是GBDT的高效实现,那么XGBoost和GBDT的区别是?
XGBoost和GBDT的区别:
XGBoost给损失函数增加了正则化项(L1正则项或者L2正则项——视学习目标的不同而取不同的正则化项)。
有些损失函数是很难计算出导数的,考虑到这种情况XGBoost使用损失函数的二阶泰勒展开来近似损失函数。
GBDT中决策树在节点分裂时遍历所有特征的所有可能划分,然后再选择最优分裂点。XGBoost在节点分裂时使用分位点及分位数近似地计算,有效降低计算量。
1.2 XGBoost的原理与推导
假设数据集为:\(\mathcal{D}=\left\{\left(\mathbf{x}_{i}, y_{i}\right)\right\}\left(|\mathcal{D}|=n, \mathbf{x}_{i} \in \mathbb{R}^{m}, y_{i} \in \mathbb{R}\right)\)。
(1) 明确目标函数(优化目标)
假设有K棵树,则第i个样本的输出为\(\hat{y}_{i}=\phi\left(\mathrm{x}_{i}\right)=\sum_{k=1}^{K} f_{k}\left(\mathrm{x}_{i}\right), \quad f_{k} \in \mathcal{F}\),其中,\(\mathcal{F}=\left\{f(\mathbf{x})=w_{q(\mathbf{x})}\right\}\left(q: \mathbb{R}^{m} \rightarrow T, w \in \mathbb{R}^{T}\right)\)。
优化的目标函数为: 
明确了优化目标之后,我们要做的就是找到一组决策树使得目标函数最小,也就是使得样本的损失与模型复杂度之和最小。
已知XGBoost算法是基于“加法模型+前向分布算法”(详见传送门),所以在求解一组决策树使得目标函数最小时采用了追加法进行模型的训练:
在已经训练好\(T_1 ~ T_{t-1}\)棵树后固定,第t棵树\(T_t\)可以表示为: 
那么对第t棵树进行训练时的目标函数为: 
(2) 目标函数的简化与展开
上一部分我们知道了训练时需要关注的是第t棵树加入后的目标函数:
- 简化
如果我们将上面的目标函数中所包含的损失函数进行一个近似,那么面对复杂的损失函数的时候便可以比较容易计算。这个时候,XGBoost利用了损失函数的泰勒二阶展开进行近似: 
函数的泰勒N阶展开是: \[ f(x)=\frac{f\left(x_{0}\right)}{0 !}+\frac{f^{\prime}\left(x_{0}\right)}{1 !}\left(x-x_{0}\right)+\frac{f^{\prime \prime}\left(x_{0}\right)}{2 !}\left(x-x_{0}\right)^{2}+\ldots+\frac{f^{(n)}\left(x_{0}\right)}{n !}\left(x-x_{0}\right)^{n}+...... \] 对函数进行泰勒展开是对函数的某点进行多项式拟合。
又由于前面t-1棵树已经固定,那么 
- 展开
在这里我们将目标函数中的模型复杂度的惩罚项\(\omega(f_t)\)进行展开。
假设我们待训练的第t棵树有T个叶子节点,所有的叶子节点的输出(向量)用\([w_1, w_2, \cdots, w_T]\)表示。因为我们的样本通过决策书的各个节点的判断后会抵达不同的叶子节点,那么样本和叶子节点的映射关系设为 \(q(x):R^d -> {1, 2, \cdots, T}\),\(q(x)\)即代表叶子节点上的样本集合。那么对于第t棵树的输出向量表示为:\(w_{q(x)}\),即\(f(x) = w_{q(x)}\)。最后,模型复杂项为: 
该模型复杂项中前面是对叶子节点的数量进行了限制,防止决策树生成地特别大;后面是对决策树的叶子节点对应的权重(输出)\(w_j\)进行了L2正则化。其中,\(\gamma\)和\(lambda\)代表惩罚力度。
最终,Xgboost的目标函数为: 
(3) 目标函数的优化
这里,优化目标函数就是求目标函数的最小值,也就是: 
1.3 XGBoost的决策树中的节点分裂
在上面的部分,我们直接利用了每棵生成好的决策树,但是决策树是如何生成的呢?
决策树是通过一个个的节点的分裂的来的。节点的分裂考虑分裂的时候能使得损失函数减小最大(减小最快)。假设Gain为分裂后的损失函数值减去分裂前损失函数值,那么也就是分裂后左子树的最小损失值(最小目标值)加上分裂后右子树的最小损失值 减去(-) 不分裂前的最小损失值: 
那么节点分裂时如何找到能够使得Gain最大的特征及其特征值呢?
XGBoost采用近似算法:对于某个特征k,算法首先根据特征分布的分位数找到特征切割点的候选集合\(S_k = S_{k_1}, S_{k_2, \cdots, S_{k_l}}\)(也就是对特征的值根据分位数采样得到分割点的候选集合--分位数就是百分数,可以自己搜索了解),然后遍历各个切分后的样本,选择使得Gain最大的值进行分裂。
在GBDT中,决策树(CART)使用精确贪心算法进行叶子节点的分裂,选择的是当前最优的分裂策略。计算过程参考:

2 XGBoost的实践与使用
2.1 XGBoost机器学习库
安装XGBoost:
pip3 install xgboost
pip install xgboost
数据接口:
五种数据格式如下:(演示代码) 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18import xgboost as xgb
# 1.LibSVM文本格式文件
dtrain = xgb.DMatrix('train.svm.txt')
dtest = xgb.DMatrix('test.svm.buffer')
# 2.CSV文件(不能含类别文本变量,如果存在文本变量请做特征处理如one-hot)
dtrain = xgb.DMatrix('train.csv?format=csv&label_column=0')
dtest = xgb.DMatrix('test.csv?format=csv&label_column=0')
# 3.NumPy数组
data = np.random.rand(5, 10) # 5 entities, each contains 10 features
label = np.random.randint(2, size=5) # binary target
dtrain = xgb.DMatrix(data, label=label)
# 4.scipy.sparse数组
csr = scipy.sparse.csr_matrix((dat, (row, col)))
dtrain = xgb.DMatrix(csr)
# 5.pandas数据框dataframe
data = pandas.DataFrame(np.arange(12).reshape((4,3)), columns=['a', 'b', 'c'])
label = pandas.DataFrame(np.random.randint(2, size=4))
dtrain = xgb.DMatrix(data, label=label)
1 | # 1.保存DMatrix到XGBoost二进制文件中 |
参数的设置方式:
下面代码用于展示xgboost中的参数设置:(可运行) 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37import xgboost as xgb
import pandas as pd
from sklearn.model_selection import train_test_split # 切分训练集与测试集
from sklearn.preprocessing import LabelEncoder # 标签化分类变量
# 加载并处理数据
df_wine = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data',header=None)
df_wine.columns = ['Class label', 'Alcohol','Malic acid', 'Ash','Alcalinity of ash','Magnesium', 'Total phenols',
'Flavanoids', 'Nonflavanoid phenols','Proanthocyanins','Color intensity', 'Hue','OD280/OD315 of diluted wines','Proline']
df_wine = df_wine[df_wine['Class label'] != 1] # drop 1 class
y = df_wine['Class label'].values
X = df_wine[['Alcohol','OD280/OD315 of diluted wines']].values
le = LabelEncoder()
y = le.fit_transform(y)
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=1,stratify=y)
dtrain = xgb.DMatrix(X_train, label=y_train)
dtest = xgb.DMatrix(X_test)
# 1.设置Booster 参数
params = {
'booster': 'gbtree',
'objective': 'multi:softmax', # 多分类的问题
'num_class': 10, # 类别数,与 multisoftmax 并用
'gamma': 0.1, # 用于控制是否后剪枝的参数,越大越保守,一般0.1、0.2这样子。
'max_depth': 12, # 构建树的深度,越大越容易过拟合
'lambda': 2, # 控制模型复杂度的权重值的L2正则化项参数,参数越大,模型越不容易过拟合。
'subsample': 0.7, # 随机采样训练样本
'colsample_bytree': 0.7, # 生成树时进行的列采样
'min_child_weight': 3,
'silent': 1, # 设置成1则没有运行信息输出,最好是设置为0.
'eta': 0.007, # 如同学习率
'seed': 1000,
'nthread': 4, # cpu 线程数
'eval_metric':'mlogloss'
}
plst = list(params.items())
1 | # 2.训练 |
保存模型:
1 | # 3.保存模型 |
加载保存的模型:
1 | # 4.加载保存的模型: |
预测:
1 | # 6.预测 |
绘制重要性特征图:
1 | # jupyter中显示图片 |

2.2 Xgboost算法案例
- 分类案例
1 | from sklearn.datasets import load_iris |
输出:accuarcy: 96.67% 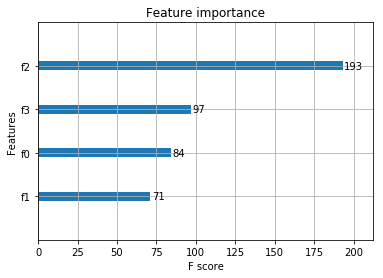
- 回归案例
1 | import xgboost as xgb |
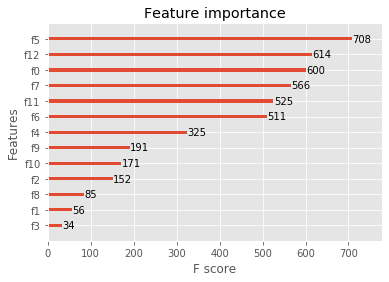
2.3 结合sklearn网格搜索的XGBoost调参
数据很多的时候时间会比较久。(还是手动调参...)
1 | import xgboost as xgb |
输出: Best score: 0.933 Best parameters set: {'max_depth': 5}
2.4 XGBoost的参数总结
xgb.train中的参数:
booster:使用哪种基学习器,默认为gbtree(代表Tree Booster),可选gblinear(代表Linear Booster)或dart。1 Tree Booster对应的参数:
eta(learning_rate):学习率,在更新中使用步长eta收缩,防止过度拟合。默认= 0.3,范围:[0,1];典型值一般设置为:0.01-0.2。
gamma(min_split_loss):分裂节点时,损失函数减小值只有大于等于gamma节点才分裂,gamma值越大,算法越保守,越不容易过拟合,但性能就不一定能保证,需要平衡。默认=0,范围:[0,∞]。
max_depth:默认= 6,一棵树的最大深度。增加此值将使模型更复杂,并且更可能过度拟合。范围:[0,∞]。
min_child_weight:如果新分裂的节点的样本权重之和小于min_child_weight则停止分裂。这个可以用来减少过拟合,但是也不能太高,会导致欠拟合。默认值= 1,范围:[0,∞]。
max_delta_step:允许每个叶子输出的最大增量步长。如果将该值设置为0,则表示没有约束。如果将其设置为正值,则可以帮助使更新步骤更加保守。通常不需要此参数,但是当类极度不平衡时,它可能有助于逻辑回归。将其设置为1-10的值可能有助于控制更新。默认= 0,范围:[0,∞]
subsample:构建每棵树时对样本的采样率。例如,如果设置成0.5,XGBoost会随机选择一半的样本作为训练集。默认值= 1,范围:(0,1]。
sampling_method:用于对训练实例进行采样的方法。默认= uniform。
uniform:每个训练实例的选择概率均等。通常将subsample大于等于0.5 时,采用uniform有良好的效果。
gradient_based:每个训练实例的选择概率与规则化的梯度绝对值成正比,具体来说就是\(\sqrt{g^2+\lambda h^2}\)。subsample可以设置为低至0.1,而不会损失模型精度。
colsample_bytree:列采样率,也就是特征采样率。默认= 1,范围为(0,1]。
lambda(reg_lambda):默认=1,L2正则化权重项。增加此值将使模型更加保守。
alpha(reg_alpha):默认= 0,权重的L1正则化项。增加此值将使模型更加保守。
tree_method:XGBoost中使用的树构建算法。默认=auto。
exact:精确的贪婪算法。枚举所有拆分的候选点。
approx:使用分位数和梯度直方图的近似贪婪算法。
hist:更快的直方图优化的近似贪婪算法。(LightGBM也是使用直方图算法)
gpu_hist:GPU hist算法的实现。
scale_pos_weight:控制正负权重的平衡,这对于不平衡的类别很有用。Kaggle竞赛一般设置sum(negative instances) / sum(positive instances),在类别高度不平衡的情况下,将参数设置大于0,可以加快收敛。
num_parallel_tree:默认=1,每次迭代期间构造的并行树的数量。此选项用于支持增强型随机森林。
monotone_constraints:可变单调性的约束,在某些情况下,如果有非常强烈的先验信念认为真实的关系具有一定的质量,则可以使用约束条件来提高模型的预测性能。(例如params_constrained['monotone_constraints'] = "(1,-1)",(1,-1)我们告诉XGBoost对第一个预测变量施加增加的约束,对第二个预测变量施加减小的约束。)
2 Linear Booster对应的参数:
ambda(reg_lambda):默认= 0,L2正则化权重项。增加此值将使模型更加保守。
alpha(reg_alpha):默认= 0,权重的L1正则化项。增加此值将使模型更加保守。
updater:默认= shotgun。
shotgun:基于shotgun算法的平行坐标下降算法。使用“ hogwild”并行性,因此每次运行都产生不确定的解决方案。
coord_descent:普通坐标下降算法。同样是多线程的,但仍会产生确定性的解决方案。
feature_selector:特征选择和排序方法,默认= cyclic。
cyclic:通过每次循环一个特征来实现的。
shuffle:类似于cyclic,但是在每次更新之前都有随机的特征变换。
random:一个随机(有放回)特征选择器。
greedy:选择梯度最大的特征。(贪婪选择)
thrifty:近似贪婪特征选择(近似于greedy)
top_k:要选择的最重要的特征数(在greedy和thrifty内)
nthread:用于设置运行XGBoost的并行线程数,默认为最大可用线程数。verbosity:打印消息的详细程度。有效值为0(静默),1(警告),2(信息),3(调试)。objective:目标函数。默认为reg:squarederror,含义是回归:最小平方误差。- reg:squarederror,最小平方误差。
- reg:squaredlogerror,对数平方损失,即\(\frac{1}{2}[long(pred+1)-log(label+1)]^2\)。
- reg:logistic,逻辑回归
- reg:pseudohubererror,使用伪Huber损失进行回归。
- binary:logistic,二元分类的逻辑回归,输出概率。
- binary:logitraw:用于二进制分类的逻辑回归,逻辑转换之前的输出得分。
- binary:hinge:二进制分类的铰链损失。这使预测为0或1,而不是产生概率。(SVM就是铰链损失函数)
- count:poisson –计数数据的泊松回归,泊松分布的输出平均值。
- survival:cox:针对正确的生存时间数据进行Cox回归(负值被视为正确的生存时间)。
- survival:aft:用于检查生存时间数据的加速故障时间模型。
- aft_loss_distribution:survival:aft和aft-nloglik度量标准使用的概率密度函数。
- multi:softmax:设置XGBoost以使用softmax目标进行多类分类,还需要设置num_class(类数)
- multi:softprob:与softmax相同,但输出向量,可以进一步重整为矩阵。结果包含属于每个类别的每个数据点的预测概率。
- rank:pairwise:使用LambdaMART进行成对排名,从而使成对损失最小化。
- rank:ndcg:使用LambdaMART进行列表式排名,使标准化折让累积收益(NDCG)最大化。
- rank:map:使用LambdaMART进行列表平均排名,使平均平均精度(MAP)最大化。
- reg:gamma:使用对数链接进行伽马回归。输出是伽马分布的平均值。
- reg:tweedie:使用对数链接进行Tweedie回归。
- 自定义损失函数和评价指标:参考链接
eval_metric:验证数据的评估指标,将根据目标分配默认指标(回归均方根,分类误差,排名的平均平均精度),用户可以添加多个评估指标。- rmse,均方根误差;
- rmsle:均方根对数误差;
- mae:平均绝对误差;
- mphe:平均伪Huber错误;
- logloss:负对数似然;
- error:二进制分类错误率;
- merror:多类分类错误率;
- mlogloss:多类logloss;
- auc:曲线下面积;
- aucpr:PR曲线下的面积;
- ndcg:归一化累计折扣;
- map:平均精度;
seed:随机数种子,默认为0。
LightGBM
LightGBM也是像XGBoost一样,是一类集成算法,他跟XGBoost总体来说是一样的,算法本质上与Xgboost没有出入,只是在XGBoost的基础上进行了优化,比如在节点分裂时利用直方图算法。
优化速度和内存使用
降低了计算每个分割增益的成本;使用直方图减法进一步提高速度;减少内存使用;减少并行学习的计算成本。
稀疏优化
用离散的bin替换连续的值。如果bins的数量较小,则可以使用较小的数据类型(例如uint8_t)来存储训练数据。
无需存储其他信息即可对特征数值进行预排序。
精度优化
使用叶子数为导向的决策树建立算法而不是树的深度导向;分类特征的编码方式的优化;通信网络的优化;并行学习的优化;GPU支持
LightGBM的优点:
1)更快的训练效率
2)低内存使用
3)更高的准确率
4)支持并行化学习
5)可以处理大规模数据
参考
Datawhale集成学习 传送门
机器学习集成学习之XGBoost(基于python实现)传送门
GBDT、xgboost原理介绍 传送门