数据分析之数据载入与初步观察
目的:通过真实的数据以实战的方式了解数据分析的流程。
这里依托Kaggle上泰坦尼克号任务进行数据分析。
1 载入数据
1.1 数据集
数据集下载传送门。
Kaggle上关于该泰坦尼克号数据集中内容的描述: 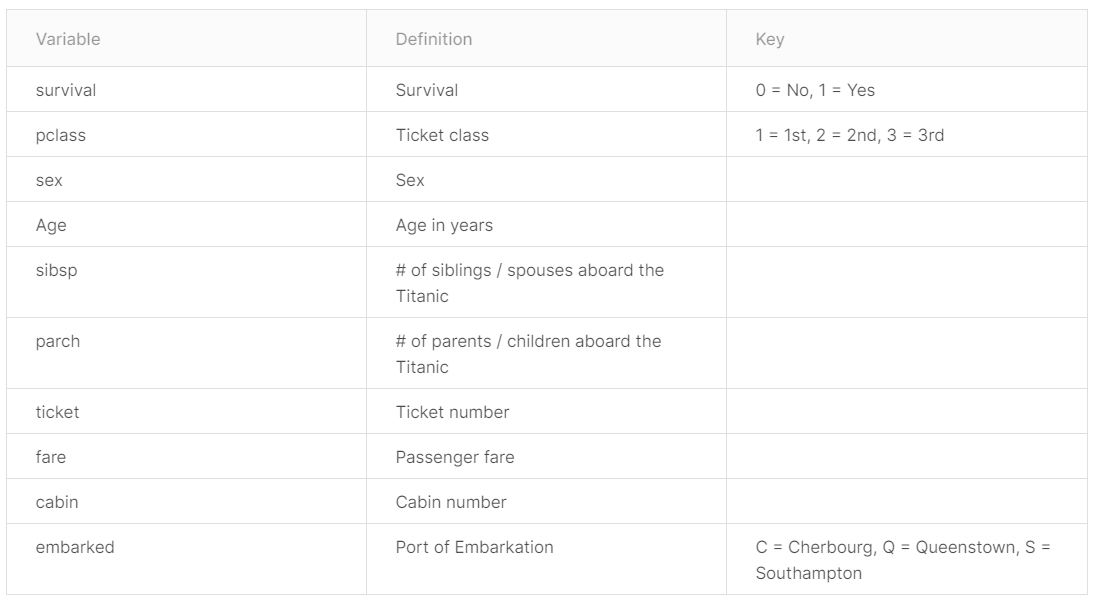
数据变量解释: 
1.2 数据载入
- 导入numpy和pandas:
1 | import numpy as np |
- 载入(读入)数据1:
1 | ## 使用相对路径载入数据(需要保证当前代码文件和数据文件在同一目录下) |
在使用绝对路径载入数据时可能会出现错误:
OSError: Initializing from file failed。这个问题的原因在这里是因为路径中含有中文。解决方法是在read_csv的函数参数中加入:engine='python',或者先使用open函数打开文件。具体原因和解决办法参考:链接。
关于tsv和csv文件的不同:(1) tsv:tab-separated values,即用制表符分隔数据值的文件类型;(2) csv:comma-separated values,即用逗号分隔数据值的文件类型。csv文件更常见一些。
- 载入(读入)数据2:
载入数据时如果文件过大,直接全部读取到内存中进行操作的会出现OOM(Out Of Memory)异常,也就是内存无法一次存放这么多数据。这个时候可以进行逐块读取,也就是分多次把文件数据读入内存。方法就是在read_csv等函数的参数中设置chunksize,指定一个块的大小(一次读取多少行)。
1 | chunker = pd.read_csv('train.csv', chunksize=1000) |
逐块读取后返回的是一个可迭代的
TextFileReader对象。可以进行迭代输出查看数据:——
2
print(row)
2 观察数据
2.1 初步观察数据
读入数据后首先对数据的整体结构和部分数据内容进行一个大致的浏览。比如,数据的大小、有多少列;各列的数据是什么格式?是否包含null等?
- 查看数据的基本信息:
利用info函数查看DataFrame数据的基本信息。
1 | train_data.info() |
输出: 
- 查看读入数据的前10行和后15行:
DataFrame数据的head函数用于查看前n行数据。
1 | train_data.head(10) |
输出: 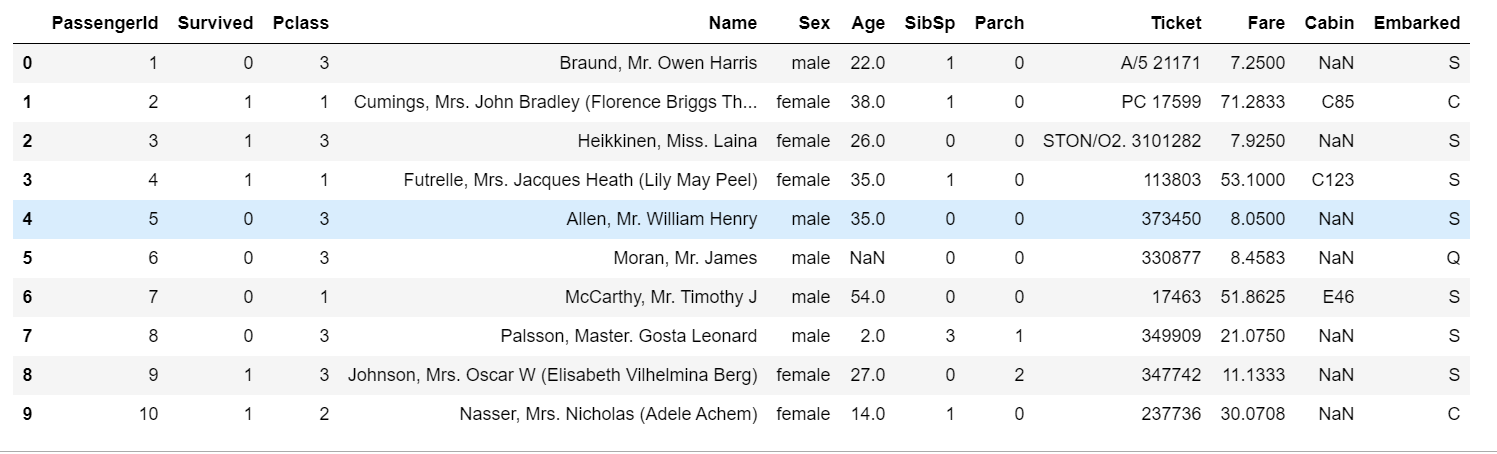
DataFrame数据的tail函数用于查看后n行数据。
1 | train_data.tail(15) |
输出(部分截图): 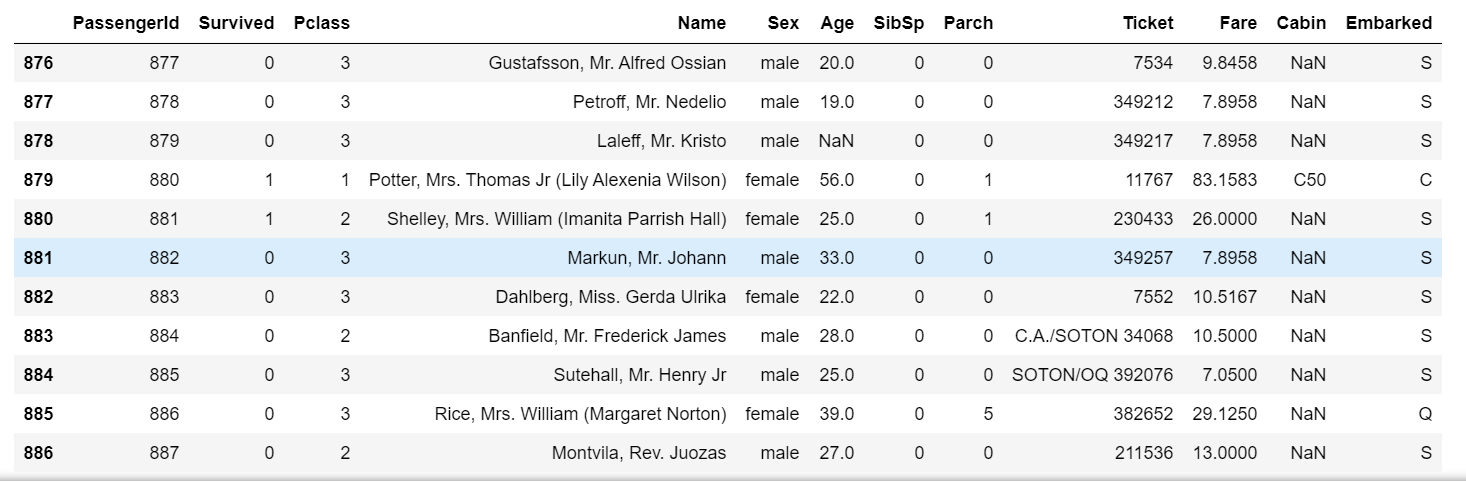
- 判断数据是否为空:
判断数据中为空的位置。空则返回True,否则返回False。这里利用DataFrame的isnull函数。
1 | train_data.isnull() |
输出为全部数据,会比较长,所以可以只看前面几行:
1 | train_data.isnull().head(10) |
输出: 
- 查看读入数据的所有列:
1 | train_data.columns |
输出:Index(['PassengerId', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp', 'Parch', 'Ticket', 'Fare', 'Cabin', 'Embarked'], dtype='object')
如果单纯想看某列,可以直接:train_data[列名]。
- 筛选一些数据:
以"Age"为筛选条件,显示年龄在10岁以下的乘客信息。 1
train_data[train_data["Age"]<10].head(3)

以"Age"为条件,将年龄在10岁以上和50岁以下的乘客信息显示出来,并将这个数据命名为midage: 1
2midage = train_data[(train_data["Age"]>10)& (train_data["Age"]<50)]
midage.head(3)
- 显示某些行某些列的数据:
将midage的数据中第100,105,108行的"Pclass","Name"和"Sex"的数据显示出来: 1
midage.loc[[100, 105, 108], ["Pclass", "Name", "Sex"]]

如果对数据做出了改变并想要保存,可以利用
to_csv函数:——
2.2 探索性数据分析
对泰坦尼克号数据(trian.csv)按票价(Fare)和年龄(Age)两列进行综合排序(降序排列),并进行分析:
输出:1
train_data.sort_values(by=['Ticket', 'Age'], ascending=False).head(10)
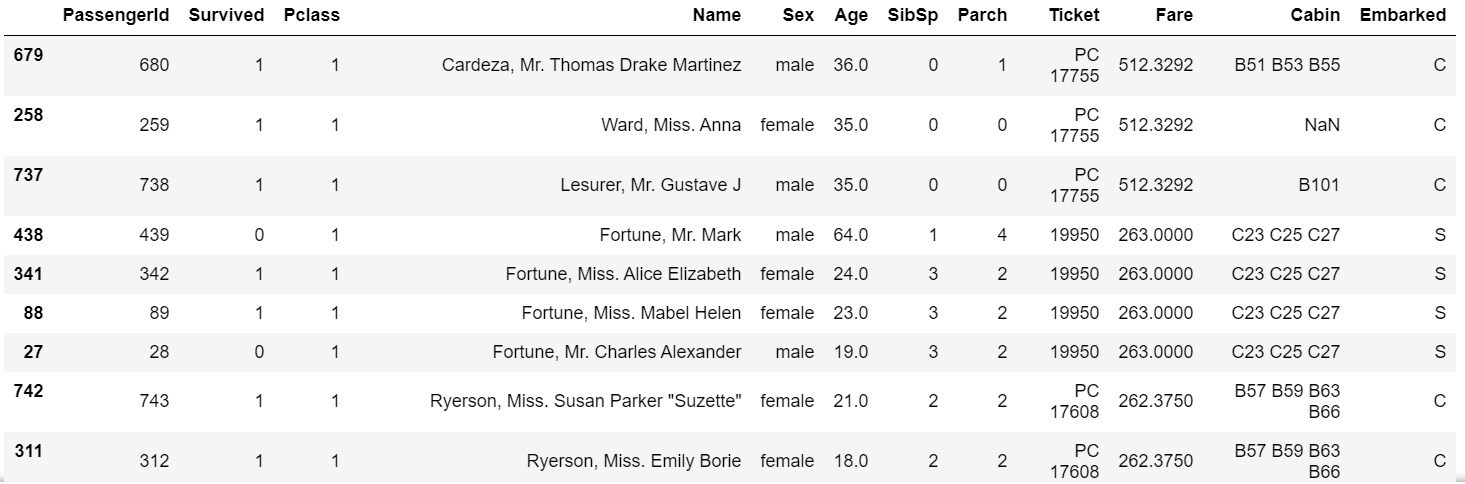 从排序好票价、年龄的前10条数据来看,80%的人存活率下来(有8人survived),比例还是很高的,所以猜测存活率与票价的高低有一定的正比关系。这里仅依靠相同票价下的年龄来看,存活率与年龄好像关系不大,又或者现在还有些影响因素未发现。
从排序好票价、年龄的前10条数据来看,80%的人存活率下来(有8人survived),比例还是很高的,所以猜测存活率与票价的高低有一定的正比关系。这里仅依靠相同票价下的年龄来看,存活率与年龄好像关系不大,又或者现在还有些影响因素未发现。通过泰坦尼克号数据如何计算出在船上最大的家族有多少人:
1 | max(train_data["sibsp"] + train_data["parch"]) |
输出:10
- 查看数据基本统计信息:
1 | train_data.describe() |
输出: 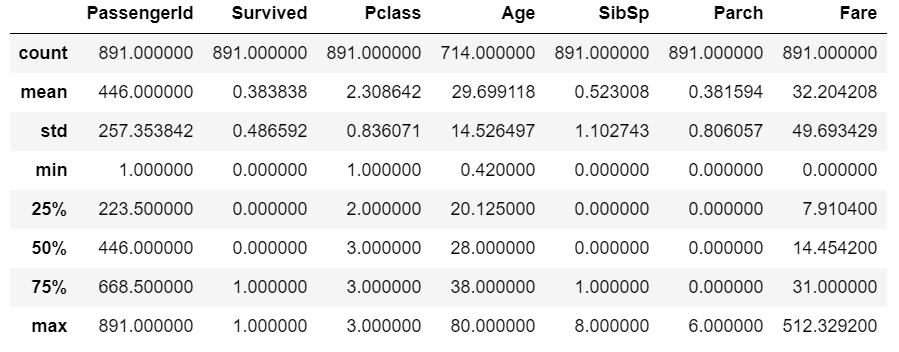
可以分析每列的统计信息来获取一定的数据信息。比如年龄:平均为29岁左右,最小的人还不满一岁,最大的人已有80岁。
参考
教材《Python for Data Analysis》,翻译版电子书链接gitbook传送门,教材对应的GitHub代码链接传送门。