1 视图
1) 什么是视图
MySQL视图(View)是一种虚拟存在的表,同真实表一样,视图也由列和行构成,但视图并不实际存在于数据库中。行和列的数据来自于定义视图的查询中所使用的表,并且还是在使用视图时动态生成的。
数据库中只存放了视图的定义,并没有存放视图中的数据,这些数据都存放在定义视图查询所引用的真实表中。使用视图查询数据时,数据库会从真实表中取出对应的数据。因此,视图中的数据是依赖于真实表中的数据的。一旦真实表中的数据发生改变,显示在视图中的数据也会发生改变。
视图无非就是存储在数据库中并具有名字的SQL语句,或者说是以预定义的SQL查询的形式存在的数据表的成分。
视图可以从原有的表上选取对用户有用的信息,那些对用户没用或者用户没有权限了解的信息,都可以直接屏蔽掉,作用类似于筛选。这样做既使应用简单化,也保证了系统的安全。
如果经常需要从多个表查询指定字段的数据,可以在这些表上建立一个视图,通过这个视图显示这些字段的数据。
2) 视图的优点
视图与表在本质上虽然不相同,但视图经过定义以后,结构形式和表一样,可以进行查询、修改、更新和删除等操作。同时,视图具有如下优点:
a. 定制用户数据,聚焦特定的数据
在实际的应用过程中,不同的用户可能对不同的数据有不同的要求。
例如,当数据库同时存在时,如学生基本信息表、课程表和教师信息表等多种表同时存在时,可以根据需求让不同的用户使用各自的数据。学生查看修改自己基本信息的视图,安排课程人员查看修改课程表和教师信息的视图,教师查看学生信息和课程信息表的视图。
b. 简化数据操作
在使用查询时,很多时候要使用聚合函数,同时还要显示其他字段的信息,可能还需要关联到其他表,语句可能会很长,如果这个动作频繁发生的话,可以创建视图来简化操作。
c. 提高数据的安全性
视图是虚拟的,物理上是不存在的。可以只授予用户视图的权限,而不具体指定使用表的权限,来保护基础数据的安全。
d. 共享所需数据
通过使用视图,每个用户不必都定义和存储自己所需的数据,可以共享数据库中的数据,同样的数据只需要存储一次。
e. 更改数据格式
通过使用视图,可以重新格式化检索出的数据,并组织输出到其他应用程序中。
f. 重用SQL语句
视图提供的是对查询操作的封装,本身不包含数据,所呈现的数据是根据视图定义从基础表中检索出来的,如果基础表的数据新增或删除,视图呈现的也是更新后的数据。视图定义后,编写完所需的查询,可以方便地重用该视图。
3) 创建视图
创建视图的基本语法如下:
1 | CREATE VIEW 视图名称 (列名1,列名2,...) |
其中, SELECT语句中列的排列顺序和视图中列的排列顺序相同。视图名在数据库中需要是唯一的,不能与其他视图和表重名。在视图的基础上可以继续创建视图,然而多重视图会降低SQL的性能。
ORDER BY子句可以用在视图中,但若该视图检索数据的SELECT语句中也含有ORDER BY子句,则该视图中的ORDER BY子句将被覆盖。
例子一: 基于单表的视图
1 | CREATE VIEW productsum (product_type, cnt_product) |
例子二: 基于多表的视图
1 | CREATE VIEW view_shop_product(product_type, sale_price, shop_name) |
4) 修改视图结构
修改视图结构的基本语法如下:
1 | ALTER VIEW 视图名 AS SELECT语句 |
例子: 1
2
3
4
5ALTER VIEW productSum
AS
SELECT product_type, sale_price
FROM Product
WHERE regist_date > '2009-09-11';
5) 如何更新视图内容
因为视图是一个虚拟表,所以对视图的操作就是对底层基础表的操作,所以在修改时只有满足底层基本表的定义才能成功修改。
对于一个视图来说,如果包含以下结构的任意一种都是不可以被更新的:
- 聚合函数 SUM()、MIN()、MAX()、COUNT() 等。
- DISTINCT 关键字。
- GROUP BY 子句。
- HAVING 子句。
- UNION 或 UNION ALL 运算符。
- FROM 子句中包含多个表。
视图归根结底还是从表派生出来的,因此,如果原表可以更新,那么 视图中的数据也可以更新。反之亦然,如果视图发生了改变,而原表没有进行相应更新的话,就无法保证数据的一致性了。
更新视图的例子: 1
2
3UPDATE productsum
SET sale_price = '5000'
WHERE product_type = '办公用品';
6) 删除视图
删除视图的基本语法如下:
1 | DROP VIEW 视图名 |
需要有相应的权限才能成功删除。
例子:
1 | DROP VIEW productSum; |
2 子查询
子查询指一个查询语句嵌套在另一个查询语句内部的查询,这个特性从MySQL 4.1开始引入,在SELECT子句中先计算子查询,子查询结果作为外层另一个查询的过滤条件。
子查询可以嵌套,例如:
1 | SELECT product_type, cnt_product |
随着嵌套的增加查询的效率也会变差,需要尽量避免多层嵌套。
3 SQL中的函数
SQL中的函数大致分为如下几类:
- 算术函数 (用来进行数值计算的函数)
- 字符串函数 (用来进行字符串操作的函数)
- 日期函数 (用来进行日期操作的函数)
- 转换函数 (用来转换数据类型和值的函数)
- 聚合函数 (用来进行数据聚合的函数)
常用函数汇总如下:
- 数值型函数
| 函数名 | 作用 |
|---|---|
| ABS | 求绝对值 |
| SQRT | 求二次方根 |
| MOD | 求余数 |
| CEIL和CEILING | 两个函数功能相同,都是返回不小于参数的最小整数,即向上取整 |
| FLOOR | 向下取整,返回值转化为一个BIGINT |
| RAND | 生成一个0~1之间的随机数,传入整数参数是,用来产生重复序列 |
| ROUND | 对所传参数进行四舍五入 |
| SIGN | 返回参数的符号 |
| POW和POWER | 两个函数的功能相同,都是所传参数的次方的结果值 |
| SIN | 求正弦值 |
| ASIN | 求反正弦值,与函数 SIN 互为反函数 |
| COS | 求余弦值 |
| ACOS | 求反余弦值,与函数 COS 互为反函数 |
| TAN | 求正切值 |
| ATAN | 求反正切值,与函数 TAN 互为反函数 |
| COT | 求余切值 |
- 字符串函数
| 函数名 | 作用 |
|---|---|
| LENGTH | 计算字符串长度函数,返回字符串的字节长度 |
| CONCAT | 合并字符串函数,返回结果为连接参数产生的字符串,参数可以使一个或多个 |
| INSERT | 替换字符串函数 |
| LOWER | 将字符串中的字母转换为小写 |
| UPPER | 将字符串中的字母转换为大写 |
| LEFT | 从左侧字截取符串,返回字符串左边的若干个字符 |
| RIGHT | 从右侧字截取符串,返回字符串右边的若干个字符 |
| TRIM | 删除字符串左右两侧的空格 |
| REPLACE | 字符串替换函数,返回替换后的新字符串 |
| SUBSTRING | 截取字符串,返回从指定位置开始的指定长度的字符换 |
| REVERSE | 字符串反转(逆序)函数,返回与原始字符串顺序相反的字符串 |
- 日期和时间函数
| 函数名 | 作用 |
|---|---|
| CURDATE 和 CURRENT_DATE | 两个函数作用相同,返回当前系统的日期值 |
| CURTIME 和 CURRENT_TIME | 两个函数作用相同,返回当前系统的时间值 |
| NOW 和 SYSDATE | 两个函数作用相同,返回当前系统的日期和时间值 |
| UNIX_TIMESTAMP | 获取UNIX时间戳函数,返回一个以 UNIX 时间戳为基础的无符号整数 |
| FROM_UNIXTIME | 将 UNIX 时间戳转换为时间格式,与UNIX_TIMESTAMP互为反函数 |
| MONTH | 获取指定日期中的月份 |
| MONTHNAME | 获取指定日期中的月份英文名称 |
| DAYNAME | 获取指定曰期对应的星期几的英文名称 |
| DAYOFWEEK | 获取指定日期对应的一周的索引位置值 |
| WEEK | 获取指定日期是一年中的第几周,返回值的范围是否为 0〜52 或 1〜53 |
| DAYOFYEAR | 获取指定曰期是一年中的第几天,返回值范围是1~366 |
| DAYOFMONTH | 获取指定日期是一个月中是第几天,返回值范围是1~31 |
| YEAR | 获取年份,返回值范围是 1970〜2069 |
| TIME_TO_SEC | 将时间参数转换为秒数 |
| SEC_TO_TIME | 将秒数转换为时间,与TIME_TO_SEC 互为反函数 |
| DATE_ADD 和 ADDDATE | 两个函数功能相同,都是向日期添加指定的时间间隔 |
| DATE_SUB 和 SUBDATE | 两个函数功能相同,都是向日期减去指定的时间间隔 |
| ADDTIME | 时间加法运算,在原始时间上添加指定的时间 |
| SUBTIME | 时间减法运算,在原始时间上减去指定的时间 |
| DATEDIFF | 获取两个日期之间间隔,返回参数 1 减去参数 2 的值 |
| DATE_FORMAT | 格式化指定的日期,根据参数返回指定格式的值 |
| WEEKDAY | 获取指定日期在一周内的对应的工作日索引 |
- 聚合函数
| 函数名 | 作用 |
|---|---|
| MAX | 查询指定列的最大值 |
| MIN | 查询指定列的最小值 |
| COUNT | 统计查询结果的行数 |
| SUM | 求和,返回指定列的总和 |
| AVG | 求平均值,返回指定列数据的平均值 |
- 流程控制函数
| 函数名 | 作用 |
|---|---|
| IF | 判断,流程控制 |
| IFNULL | 判断是否为空 |
| CASE | 搜索语句 |
CASE 表达式
CASE 表达式是在区分情况时使用的,使用语法如下:
1 | CASE WHEN 求值表达式1 THEN 表达式1 |
例子:
1 | SELECT product_name, |
练习题
1
创建出满足下述三个条件的视图(视图名称为 ViewPractice5_1)。使用 product(商品)表作为参照表,假设表中包含初始状态的 8 行数据。
- 条件 1:销售单价大于等于 1000 日元。
- 条件 2:登记日期是 2009 年 9 月 20 日。
- 条件 3:包含商品名称、销售单价和登记日期三列。
对该视图执行 SELECT 语句的结果如下所示。
1 | SELECT * FROM ViewPractice5_1; |
执行结果
1 | product_name | sale_price | regist_date |
Solution:
1 | CREATE VIEW ViewPractice5_1(product_name, sale_price, regist_date) |
2
向习题一中创建的视图 ViewPractice5_1 中插入如下数据,会得到什么样的结果?为什么?
1 | INSERT INTO ViewPractice5_1 VALUES (' 刀子 ', 300, '2009-11-02'); |
Solution:
会失败,因为sale_price和regist_date这两个字段的数据都不对。
3
请根据如下结果编写 SELECT 语句,其中 sale_price_avg 列为全部商品的平均销售单价。

4
请根据习题一中的条件编写一条 SQL 语句,创建一幅包含如下数据的视图(名称为AvgPriceByType)。
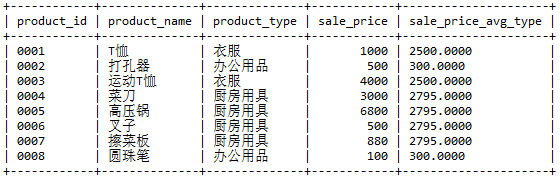
提示:其中的关键是 sale_price_avg_type 列。与习题三不同,这里需要计算出的 是各商品种类的平均销售单价。这与使用关联子查询所得到的结果相同。 也就是说,该列可以使用关联子查询进行创建。问题就是应该在什么地方使用这个关联子查询。
5 判断题
运算中含有 NULL 时,运算结果是否必然会变为NULL ?
6
对本章中使用的 product(商品)表执行如下 2 条 SELECT 语句,能够得到什么样的结果呢?
①
1 | SELECT product_name, purchase_price |
② 1
2
3SELECT product_name, purchase_price
FROM product
WHERE purchase_price NOT IN (500, 2800, 5000, NULL);
7
按照销售单价( sale_price )对练习 3.6 中的 product(商品)表中的商品进行如下分类。
- 低档商品:销售单价在1000日元以下(T恤衫、办公用品、叉子、擦菜板、 圆珠笔)
- 中档商品:销售单价在1001日元以上3000日元以下(菜刀)
- 高档商品:销售单价在3001日元以上(运动T恤、高压锅)
请编写出统计上述商品种类中所包含的商品数量的 SELECT 语句,结果如下所示。
执行结果
1 | low_price | mid_price | high_price |
参考链接
https://github.com/datawhalechina/wonderful-sql
http://m.biancheng.net/view/7232.html
https://www.w3cschool.cn/sql/xf6h1oz8.html