NLTK
NLTK介绍
NLTK(Natural Language Toolkit)是Python上著名的自然语言处理库,它自带语料库、词性分类库,还自带分词(tokenize)、分类等等功能。
NLTK有强大的社区(community)支持。
NLTK安装
Linux安装nltk命令: $pip install -U nltk
-U参数是指update(更新)。
测试是否安装成功: 在终端窗口: 1
2$ python
>>> import nltk
安装语料库
1 | import nltk |
下载时可能会出现[error connecting to sever],就是出现连接失败的情况,原因是nltk语料库的服务器需要连外网才能访问,所以修改下DNS地址。
Linux修改DNS地址:
sudo vim /etc/resolv.conf,将文件中的nameserver后的ip改为8.8.8.8
选择要下载的内容,这里我只下载了nltk的book。  下载到的路径可以自己更改。
下载到的路径可以自己更改。
NLTK模块和自然语言处理任务
| 自然语言处理任务 | NLTK模块 | 功能示例 |
|---|---|---|
| 获取语料库 | corpus | 语料库和词典的标准接口 |
| 字符串处理 | tokenize, stem | tokenizers(分词器),sentence tokenizers(句子分词器),stemmers(词干提取器) |
| 词组发现 | collocations | t检验、卡方检验、PMI(两个词之间的关联度) |
| 词性标记(POS tagging) | tag | n-gram, backoff, Brill, HMM, TnT |
| 机器学习 | 分类(classify), 聚类(cluser), tbl | 决策树、最大熵、朴素贝叶斯、最大期望、k均值 |
| 断句(Chunking) | chunk | 正则表达式、n-gram、命名实体 |
| 句法分析 | parse, ccg | chart, feature-based, unification(一致性), probabilistic(概率), dependency(依赖) |
| 语意解释 | sem, inference | lambda calculus(λ微分), first-order logic(一阶逻辑), model checking(模型检验) |
| 评价指标 | metrics | 精度、召回率、一致性系数 |
| 概率与估计 | probability | 频率分布、平滑概率分布 |
参考并翻译自《Natural Language Processing with Python---Analyzing Text with the Natural Language Toolkit》 (这本书贼适合上手!)
NLTK的简单使用
- python的命令行模式导入nltk中的book,这时会显示一些欢迎信息并加载了一些书的文本。
1 | >>> from nltk.book import * |
- 接着在text1中查看"monstrous"一词的上下文。
concordance函数可以展示某个词和其上下文。
1 | >>> text1.concordance("monstrous") |
- 利用
similar函数可以查看某个词的相似词(出现在相似的上下文语境的词),由下面的输出可以看出不同text中monstrous的相似词不太一样,这和作者写作相关。
1 | >>> text1.similar("monstrous") |
- 利用
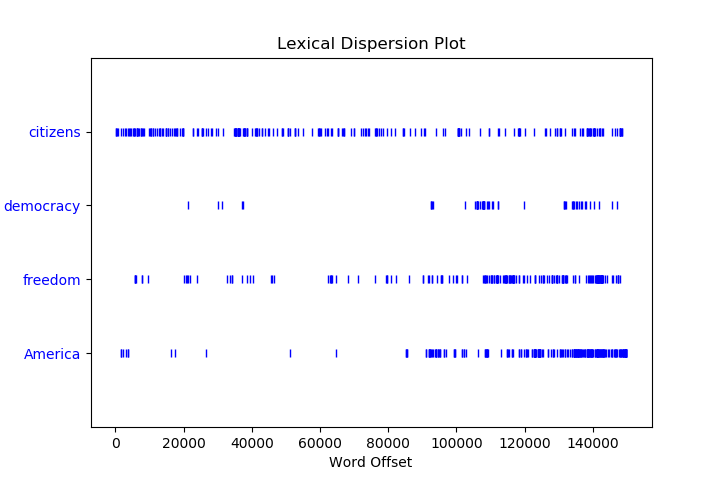
dispersion_plot函数可以很直观地看某个词在文本中的出现的位置,下面的示例是220年的美国总统就职演讲稿首尾相接的文本中一些词的出现,通过词汇散布图可以发现一些信息,例如用词的趋势。(需要numpy和matpltlib包,提前import)
1 | >>> text4.dispersion_plot(["citizens", "democracy", "freedom", "duties", "America"]) |
基于NLTK进行文本分析
词汇统计
统计文本的长度,包括word和标点符号:
1
2>>> len(text3)
44764所有text3包含word和标点共有44764个,或者说token共有444764个
想要知道文本中有多少不同的token可以通过集合(set)实现,并用
sorted函数排好序:分析text3的总长度,它有44764个tokens,但是仅有2789个不同的token,也就是有2789个word type(word)和type(标点符号)。1
2
3
4
5>>> sorted(set(text3))
['!', "'", '(', ')', ',', ',)', '.', '.)', ':', ';', ';)', '?', '?)',
'A', 'Abel', 'Abelmizraim', 'Abidah', 'Abide', 'Abimael', 'Abimelech','Abr', 'Abrah', 'Abraham', 'Abram', 'Accad', 'Achbor', 'Adah', ...]
>>> len(sorted(set(text3)))
2789对token进行分析
想要了解某个词在文本中出现的次数以及它在文本中出现的百分比:
求文本中词汇的丰富性和文本中某个词出现次数的占比十分常见,写出函数备用:1
2
3
4>>> text3.count("smote")
5
>>> 100 * text4.count("a") / len(text4)
1.46430164339383121
2
3
4def lexical_diversity(text):
return len(set(text)) / len(text)
def percentage(word, text):
return 100 * text.count(word) / len(text)
令文本不同的统计特征
是什么让文本之间有区别的?
频率分布(Frequency Distribution)
频率分布代表的是文本中所有词的出现的频率。
对于一个文本来说出现次数特别多的词在一定程度上能够代表文本的内容,NLTK中的
FreqDist(Frequency Distribution)可以用来看常见词:对text5最常见的50个词画出来如下图所示,因为text5为chat corpus,所以有很多日常用语,但是这种词没有给出有效信息,除了出现了142次的"chat",所以还需要其他的方式来提取有效信息。1
2
3
4
5
6
7>>> fdist = FreqDist(text5)
>>> print(fdist)
<FreqDist with 6066 samples and 45010 outcomes>
>>>
>>> fdist.most_common(100)
[('.', 1268), ('JOIN', 1021), ('PART', 1016), ('?', 737), ('lol', 704), ('to', 658), ('i', 648), ('the', 646), ('you', 635), (',', 596), ('I', 576), ('a', 568), ('hi', 546), ('me', 415), ('...', 412), ('is', 372), ('..', 361), ('in', 357), ('ACTION', 346), ('!', 342), ('and', 335), ('it', 332), ('that', 274), ('hey', 264), ('my', 242), ('of', 202), ('u', 200), ("'s", 195), ('for', 188), ('on', 186), ('what', 183), ('here', 181), ('are', 178), ('not', 170), ('....', 170), ('do', 168), ('all', 165), ('have', 164), ('up', 160), ('like', 156), ('no', 155), ('with', 152), ('chat', 142), ('was', 142), ("n't", 141), ('so', 139), ('your', 137), ('/', 133), ("'m", 133), ('good', 130), ('im', 128), ('how', 128), ('too', 125), ('just', 125), ('any', 123), ('there', 120), ('U7', 119), ('U34', 119), ('pm', 108), ('wanna', 107), ('out', 107), ('lmao', 107), ('be', 107), ('can', 105), ('Hi', 104), ('know', 103), ('get', 102), (':)', 101), ('U35', 101), ('ya', 100), ('who', 99), ('room', 98), ('if', 98), ('at', 98), (':', 96), ('ok', 96), ('am', 93), ('-', 93), ('from', 92), ('did', 92), ('U18', 92), ('wb', 91), ('but', 90), ('or', 88), ('one', 87), ('"', 87), ('LOL', 87), ('this', 86), ('he', 84), ('well', 81), ('m', 81), ('U30', 81), ('now', 79), ('oh', 79), ('U19', 79), ('back', 78), ('hiya', 78), ('they', 77), ('U52', 77), ('dont', 75)]
>>> fdist.plot(50)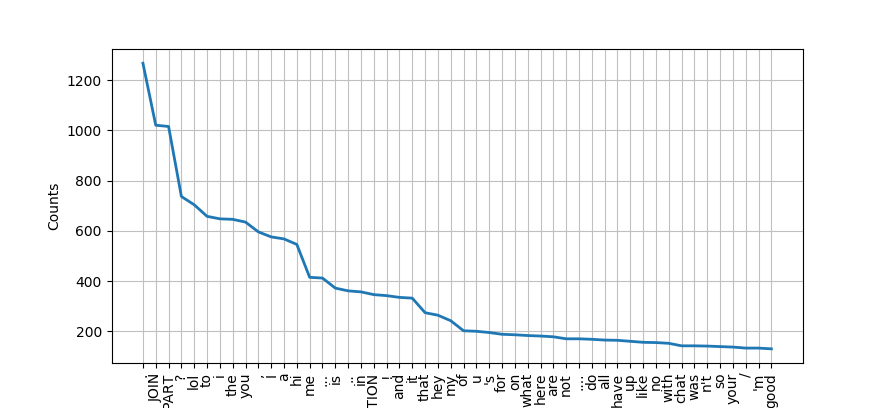
NLTK中频率分布包含如下函数:
| 示例 | 描述 |
|---|---|
| fdist = FreqDist(samples) | 生成给定样本的频率分布 |
| fdist['room'] | 样本中room一词出现的次数 |
| fdist.freq('room') | 样本中room一次的频率 |
| fdist.N() | 样本中所有token的总数 |
| fdist.most_common(n) | 样本中数量排名前n的token |
| for sample in fdist | 对样本中的数据迭代 |
| fdist.max() | 样本中出现次数的token |
| fdist.plot() | 频率分布的图像展示 |
1 | >>> fdist = FreqDist(text9) |
词组与bigram(词对)
词组(collocation)就是常见的几个词(word)的组合,bigram是从文本中提取的词对(word pair)。
bigram()函数提供了给出word pair的功能:collocation就是频繁出现的bigram。1
2>>> list(bigrams(['I', 'get', 'up', 'late', 'this', 'morning']))
[('I', 'get'), ('get', 'up'), ('up', 'late'), ('late', 'this'), ('this', 'morning')]collocation()函数帮我们找出了文本中频繁出现的bigram:1
2
3
4
5
6>>> text9.collocations()
said Syme; asked Syme; Saffron Park; Comrade Gregory; Leicester
Square; Colonel Ducroix; red hair; old gentleman; could see; Inspector
Ratcliffe; Anarchist Council; blue card; Scotland Yard; dark room;
blue eyes; common sense; straw hat; hundred yards; said Gregory; run
away