推荐系统简介
推荐系统的目的
- 让用户更快更好地获取到自己需要的内容。(在无数的商品信息中高效地获取到自己想要的物品)
- 让内容更好更快的推送到喜欢它的用户手中。
- 让平台更有效地保留用户资源。(用户在获取内容时的便利和优质资源的获得)
推荐系统的应用
推荐系统广泛应用在个性化音乐、电子商务、电影视频、社交网络、个性化阅读、位置服务、个性化邮件、个性化广告、个性化旅游、证券理财等。
个性化推荐是基于用字自己的数据生成的。热门推荐是基于大量的用户数据生成的。
推荐系统的基本思想
- 1 利用用户和物品的特征,给用户推荐那些具有用户喜欢特征的物品。(很多时候不知道用户喜欢的特征)
- 2 根据用户喜欢过的物品进行相似物品的推荐。(物以类聚)
- 3 根据与用户具有相似兴趣的用户所喜欢的物品进行推荐。(人以群分)
推荐系统的数据分析
用户信息
用户信息数据包含:
- 个人信息。例如性别、年龄等。
- 喜好标签。很多应用会让用户选择自己感兴趣的领域或者内容,利用这样的喜好标签进行内容的推荐。
- 上下文信息。如果没有个人信息和喜好标签,可以通过像获取浏览器的搜索内容(如果能够访问用户cookie的内容)进行数据的获取。
物品信息
物品信息数据包含:
- 内容信息
- 分类标签
- 关键词
行为数据
用户对物品的评分/评价、打标签、收藏、购买等可以从数据库中获取的内容和点击、浏览等从用户日志中获取的内容能够反映用户喜不喜欢某物品、是否感兴趣。用户的行为数据对推荐来说十分重要。
推荐系统的分类
根据实时性分类
- 离线推荐
- 实时推荐
根据推荐是否个性化推荐
- 基于统计的推荐
- 个性化推荐
根据推荐原则分类
- 基于相似度的推荐
- 基于知识(规则)的推荐。利用已经有的知识或者说规则进行推荐,这是依赖已经有的经验来的。
- 基于模型的推荐。没有推荐的知识(经验)可以依靠,通过训练模型,让模型从数据中学出特征来进行推荐。
根据数据的来源进行分类
- 基于人口统计学的推荐。利用用户信息的数据推荐。
- 基于内容的推荐。利用物品信息的数据。
- 基于协同过滤的推荐。利用用户行为数据。
推荐算法简介
基于人口统计学的推荐
根据相似的用户信息进行推荐,比如下图中利用相似年龄和性别的用户a的喜欢的内容给用户c进行物品推荐。(有许多不同的相似度原则) 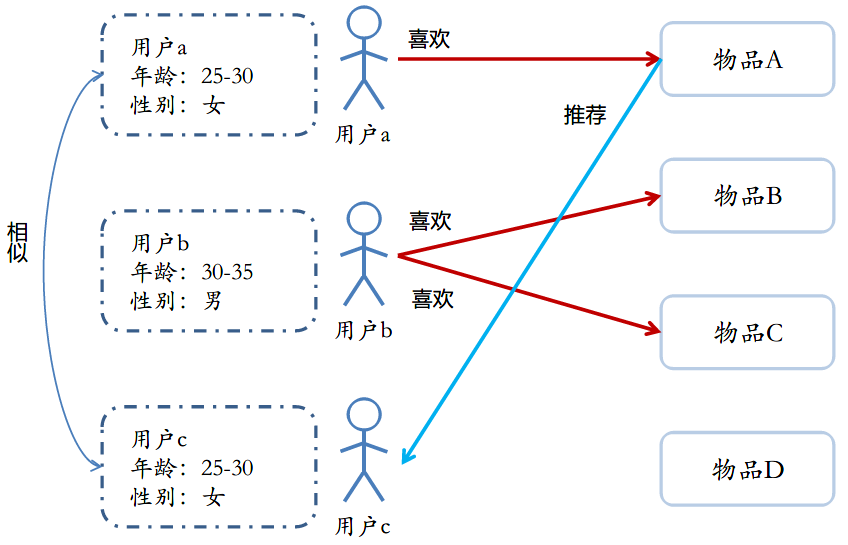 (图片来自尚硅谷的推荐系统教程)
(图片来自尚硅谷的推荐系统教程)
基于内容的推荐
根据具有相似内容或标签的物品进行推荐,比如下图中利用相似类型的电影A给用户a推荐电影C。 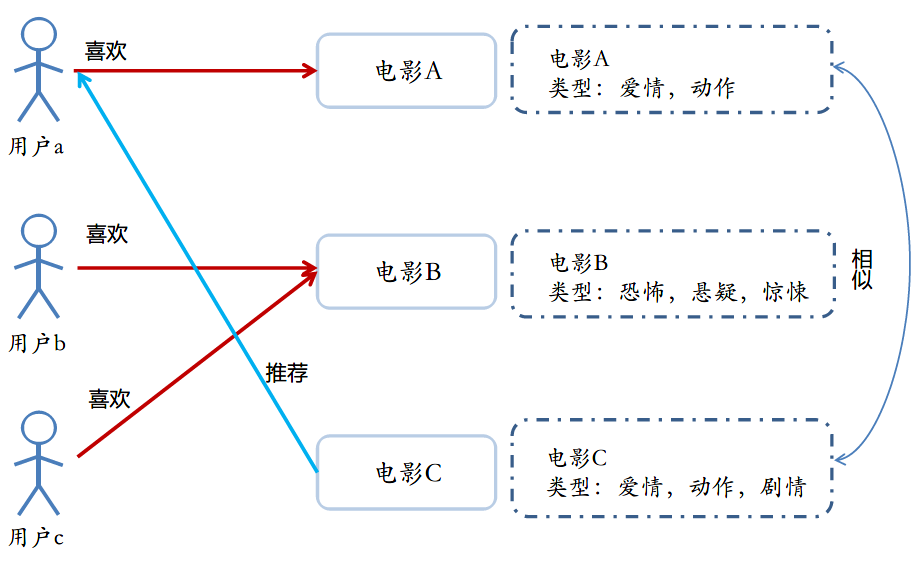
基于协同过滤的推荐
协同过滤(Collaborative Filtering, CF)是由协同和过滤两部分结合,协同是指用户和物品一同的信息(也就是用户行为数据),过滤是指在联系起来的用户信息和物品信息中提取一部分(有用的那些)。举例来说,下面的不同用户对不同物品的评分表中是依据用户对物品的评分提取出所需信息。 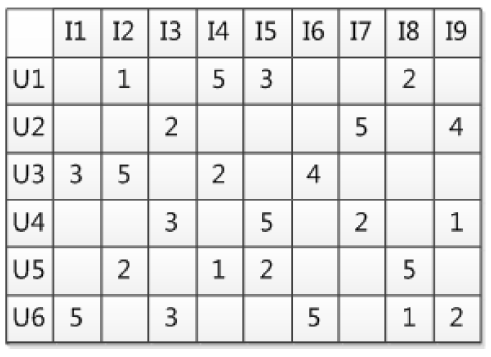
协同过滤不用获取用户信息和物品信息,只需要一些用户评价物品或者点击的信息等即可,不需要获取到用户个人信息和物品内容。但是协同过滤需要一定的历史数据。
协同过滤分为基于近邻的协同过滤和基于模型的协同过滤:
基于近邻的协同过滤
基于用户(User-CF)
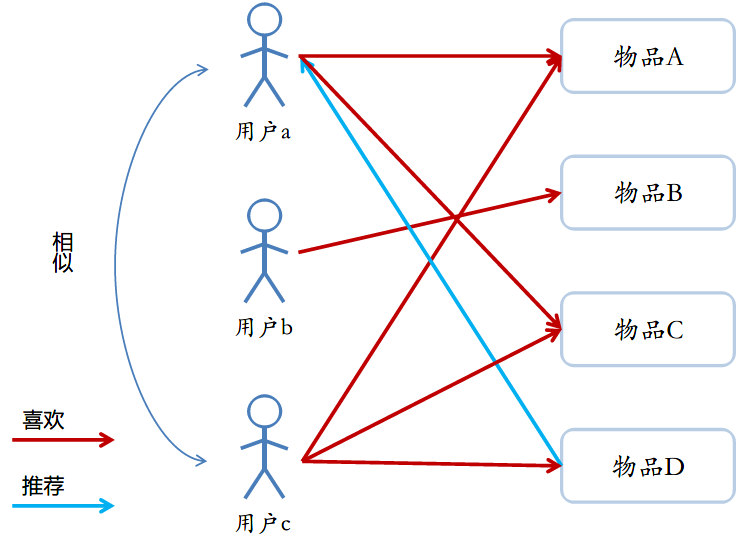
利用相似用户(这里的相似用户就不再是拥有相似的个人信息,而是拥有相似的行为数据,像点击、购买、收藏等等用户行为的数据。)进行物品的推荐。举例来说,下图中用户a喜欢物品A、C,用户c喜欢物品A、C、D,那么因为用户a和c喜欢的物品相似的比较多(都喜欢物品A、C),那么用户a和用户c就是相似用户,从而根据用户c向用户a推荐物品D。
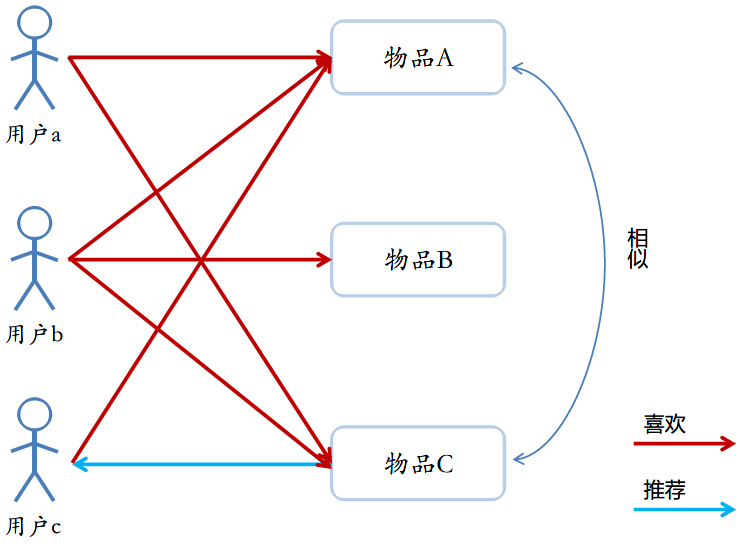
基于物品(Item-CF)
利用相似物品(这里的相似物品是指有很多共同的人喜欢)进行推荐。举例来说,下图中物品A被用户a、b、c喜欢,物品B被用户b喜欢,物品C被用户a、b喜欢,那么物品A与C具有很多(更多)的用户喜欢,那么物品A和C相似,这样就可以向喜欢物品A的用户推荐物品C了。
基于模型的协同过滤
奇异值分解(SVD)
潜在语义分析(LSA)
支持向量机(SVM)
混合推荐
混合推荐就是应用不同的推荐方式。实际应用中的推荐系统应用的都是不止一种的推荐方式也就是混合推荐。
混合的方式有:
加权混合
选择不同的推荐方式进行推荐,然后将它们的推荐结果分别乘上一定的系数(权重)加起来(线性公式),加和之后的结果就是最终的推荐结果。不同推荐方式的结果所具有的权重需要在测试数据集上反复实验,找到拥有最好推荐效果的权重。
切换混合
在不同的情况下(数据量、系统运行状况、用户和物品和数目等),选择最合适的推荐机制进行推荐。
分区混合
采用多种推荐方式,将不同方式的推荐结果显示在系统中不同的区块。
分层混合
采用多种推荐机制,并将上一层推荐方式得到的推荐结果作为输入传给本层的推荐方式。这也就是综合了各个推荐方式。
推荐系统的评测
推荐系统评测指标
- 预测准确度
- 用户满意度
- 覆盖率
- 多样性
- 实时性
- ...等等
推荐准确度测评
评分预测
很多应用中都有让用户对物品进行打分的功能。利用用户对物品的历史评分,从中学习一个兴趣模型,从而预测用户对新物品的评分。
评分预测的准确度一般利用均方根误差(RMSE)或平均绝对误差(MAE)计算。
均方根误差(Root Mean Square Error)
均方根误差是预测值和真实值偏差的平方和与预测值个数的比值的平方根。它用来衡量预测值和真实值之间的偏差。
\(RMSE = \sqrt{\frac{\sum_{u,i \in {T}} (r_ui - \hat r_{ui})^2}{\left\vert T \right\vert}}\)
其中,\(r_{ui}\)是用户u对物品i的评分,\(\hat r_{ui}\)是预测的评分,T是总共评分的个数。
平均绝对误差(Mean Absolute Error)
平均绝对误差是误差绝对值的平均值。它能反映预测值误差的真实情况。
\(MAE = \frac{\sum_{u,i \in {T}} \left\vert r_{ui} - \hat r_{ui}\right\vert}{\left\vert T \right\vert}\)
Top-N推荐
应用在提供推荐服务时一般是给用户一个个性化推荐列表,这种列表叫做Top-N推荐。
Top-N推荐的预测准确率一般用精确率(precision)和召回率(recall)。
对于常见的二分类问题,将真实标签和预测结果进行组合有真正例(True Positive, TP)、假正例(false positive, FP)、真反例(true negative, TN)、假反例(false negative, FN),由它们组成的“混淆矩阵(confusion matrix)”为:
| (预测)正例 | (预测)反例 | |
|---|---|---|
| (真实)正例 | TP | FN |
| (真实)反例 | FP | TN |
精确率(precision)
精确率为在所有预测为正例的结果中有多少真正的正例。 $ P = $
召回率(recall)
召回率为在所有真实的正例中有多少被预测为正例。 $ R = $