深度学习推荐系统模型搭建基础
编程基础(Keras函数式API编程)
本项目中所有代码都通过Tensorflow2.x实现,所以熟悉Tensorflow的基础操作,以及tf2中keras的使用(与早期的keras的使用基本上是一致的),对于TF及keras的基础这里不做太多的介绍,可以参考相关的资料进行学习。这里主要说一下keras函数式编程的基本用法。
keras搭建模型主要有两种模式,一种是Sequential API,另外一种是Functional API。前者主要是通过层的有序堆叠形成一个模型,在大多数情况下可以快速的搭建一个模型,但是搭建的模型更适合简单的堆叠模型,对于复杂模型(多输入、多输出、共享层)的搭建就比较困难,所以后者函数式API可以更加灵活的搭建复杂网络,函数式API搭建模型是通过创建层的实例并将将层与层之间连接在一起,最后只需要指定模型的输入和输出就可以完成模型的搭建,不同层的实例可以表示不同的操作,搭建模型的时候只需要考虑层与层之间的关系,以及复杂层的搭建就可以很方便的搭建起一个复杂网络。
回顾Sequential API搭建模型:
1 | import tensorflow as tf |
可以看到上述搭建网络直接使用keras中的层直接堆叠即可,但是函数式API与其不太一样,首先需要定义模型的输入层Input(), 并在Input层中指定输入的数据的维度 ,如下定义一个输入层,输入数据的维度是784, 不需要考虑数据的Batch size维度,定义的输入层可以认为是数据在模型所表示的层,接下来就是要将数据进行相应的转换,也就是将输入层输入到下一个层中,将数据进行转换,
1 | # 定义输入层(可以看成数据层) |
上面简单的说明了通过函数式API构建模型的流程,下面再了解一下如何使用函数式API的方式构建多输入、多输出及共享层的模型:
例如,如果您正在构建一个按优先级排列客户问题通知单并将其发送到正确部门的系统,那么该模型将有三个输入:
票证的标题(文本输入),
票证的文本正文(文本输入),以及
用户添加的任何标记(分类输入)
该模型将有两个输出:
优先级得分介于0和1之间(标量sigmoid输出),以及
应处理票证的部门(部门集合上的softmax输出)。
1 | num_tags = 12 # 标记数量 |

从上面这个图就可以看出,模型多输入,多输出,共享层的结构,并且也会发现搭建的过程也是非常的简单。
上面的代码参考的是Keras官网案例,在原始案例的基础上加上了共享层,省的重新再去写一个案例
==当特征比较多的时候如何构建多输入模型呢?==
先说答案:将输入的数据转换成字典的形式,定义输入层的时候让输入层的name和字典中特征的key一致,就可以使得输入的数据和对应的Input层对应,后面搭建模型就是和上面介绍的一样的了。
直接看个例子吧:
1 | from keras.models import Model |
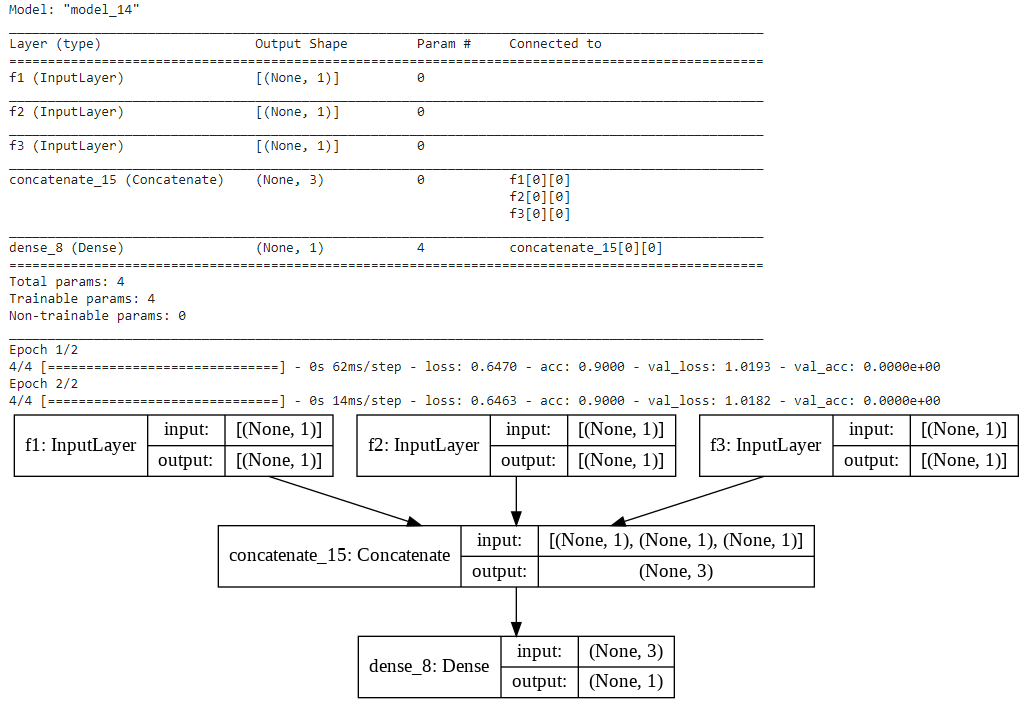
上面就是举了个简单的例子说明,当多输入特别多的时候,构建模型我们可以将数据转换成字典的形式,然后字典中特征的名称与其对应的Input层的名称一致就行,这里是为了后面搭建复杂模型打基础。
统一视角看推荐模型
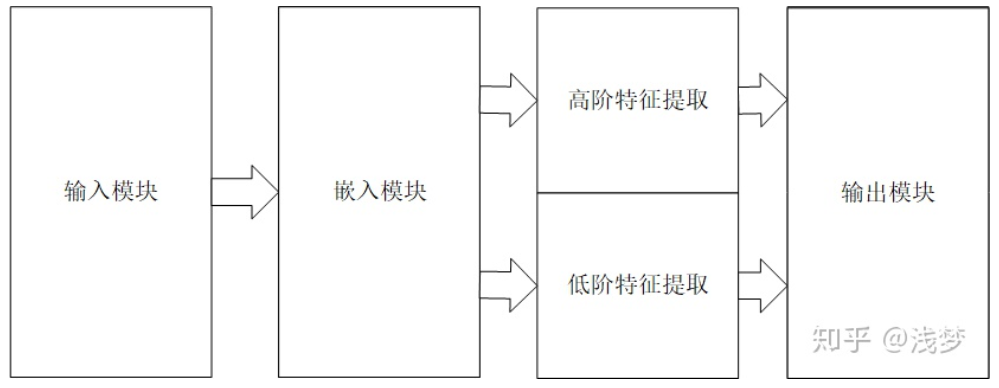
相信大家对DeepCTR开源项目应该是有点了解,DeepCTR通过对现有的基于深度学习的点击率预测模型的结构进行抽象总结,在设计过程中采用模块化的思路,各个模块自身具有高复用性,各个模块之间互相独立。 基于深度学习的点击率预测模型按模型内部组件的功能可以划分成以下4个模块:输入模块,嵌入模块,特征提取模块,预测输出模块。关于DeepCTR的介绍可以参考这个文章DeepCTR:易用可扩展的深度学习点击率预测算法包
下面主要说一下代码参考DeepCTR项目实现需要注意的几个点。
==特征表示的统一==
看过DeepCTR源码的人可能就会知道,项目中输入分成三大类,分别是SparseFeat, DenseFeat, VarLenSparseFeat,并且使用类进行了封装,其中也考虑到效率的问题做了一些优化,这里不说具体的类的实现及优化是什么,我先来思考一下使用这三类特征可以表示大多数推荐场景下的特征嘛?
SparseFeat: 稀疏特征的标记,一般是用来表示id类特征
DenseFeat: 表示数值型特征,可以是一维的也可以是多维的
VarLenSparseFeat: 可变长的id类特征,就是id序列特征
这三类特征在实际的推荐系统应用中包含了绝大多数的特征类型,在石塔西大佬的推荐算法的"五环之歌"中也说到,类别特征才是推荐系统中的一等公民,也就是说大部分的特征都是类别特征,也可能会有一些其他的比如图像、视频等其它特征,虽然实际存不存在,但是我感觉如果要是用这些特征就需要将其转换成向量的形式去使用,也就是DenseFeat多维度的情况。
那么有了这三个统一的标志有什么用呢?答案是用来更好的构建输入层!
==通过特征标记构造输入层==
在前面的函数式API构建模型最后说到过,可以使用字典的形式构建输入,最后只要将对应Input层的名字与字典中特征的key相对应就可以。在定义Input层的时候,除了name以外还有一个重要的属性就是shape
然而所有特征Input层的shape其实只有4种情况:
- 数值特征,1维的数值特征shape=(1, )
- 多维的数值特征shape=(dimension, )
- 类别特征,shape=(1,), 为什么类别特征的shape维度是1呢,因为输入的就是一个id,在类别型特征的Input后面还需要接一个Embedding层,将id转化成稠密的向量
- 可变长的序列特征,shape=(maxlen, 1), 序列的输入往往需要定义一个最大长度,这样不至于序列长度之间相差太大,这个最大长度可以是实际数据中的最大长度,也可以是根据经验定义的最大长度。需要注意的是,序列特征中的每个元素其实也是一个id类特征,在最后转换成Embedding的时候,不是一个Embedding向量,而是一个矩阵。
上面说了Input层的四种情况有什么用呢?
当特征维度特别多的时候,比如成百上千维特征,如果没有这种标记的话,我们就需要挨个定义每个特征对应的Input层,当然有人可能会说可以提前分组然后再给不同的Input层,其实本质上是一样的。
==Embedding层的注意点==
在构建模型的时候Embedding相关的需要注意两点:
- Embedding层的参数问题
- Embedding层之间的拼接问题
上面在说了类别特征和可变长的序列特征,在这两个Input层之后都需要将其转化成Embedding向量或者Embedding矩阵,在keras中转化成Embedding向量和Embedding矩阵只是相差一个参数的问题

==如何在linear层引入onehot特征==
如果要将类别型特征的onehot表示输入到linear层中,第一个想法就是直接把特征转换成onehot向量不就行了吗?的确是可以,但是我们知道在推荐场景中id类特征是一等共鸣,在实际的场景中如果将所有的特征都转换成onehot类型,维度很可能超出想象。这里有个更好的做法就是,给id类特征转换成一个一维的Embedding矩阵,只需要将这个Embedding保存下来,然后有id类特征输入直接在Embedding中进行查找,找到那个对应的值其实就是onehot向量已经乘完权重的值,因为onehot向量只有0和1,只有非零的才是有效的,而1乘以权重还是权重本身,所以这种方式来获取onehot向量中的非零元素的值,相比直接使用onehot向量乘以一个权重更好一些。