词向量的操作(运算)
利用预训练好的词向量来发现词之间的同义或对等关系。
1 预训练的词向量
首先导入需要的库: 1
2
3
4
5
6
7import pandas as pd
import numpy as np
import pickle
import matplotlib.pyplot as plt
%matplotlib inline
%config InlineBackend.figure_format='png'1
2word_embeddings = picle.load(open("word_embeddings_subset.p", "rb"))
print(len(word_embeddings))243
词向量文件指路:here
展示预训练好的词向量word_embeddings,它是字典类型,键是词,值是相应的向量表示。(篇幅问题只展示一个词向量表示) 1
2
3
4
5print(word_embeddings.keys())
countryVector = word_embeddings['country'] # Get the vector representation for the word 'country'
print(type(countryVector)) # Print the type of the vector. Note it is a numpy array
print("countryVector:", countryVector) # Print the values of the vector.
#print(word_embeddings)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52dict_keys(['country', 'city', 'China', 'Iraq', 'oil', 'town', 'Canada', 'London', 'England', 'Australia', 'Japan', 'Pakistan', 'Iran', 'gas', 'happy', 'Russia', 'Afghanistan', 'France', 'Germany', 'Georgia', 'Baghdad', 'village', 'Spain', 'Italy', 'Beijing', 'Jordan', 'Paris', 'Ireland', 'Turkey', 'Egypt', 'Lebanon', 'Taiwan', 'Tokyo', 'Nigeria', 'Vietnam', 'Moscow', 'Greece', 'Indonesia', 'sad', 'Syria', 'Thailand', 'Libya', 'Zimbabwe', 'Cuba', 'Ottawa', 'Tehran', 'Sudan', 'Kenya', 'Philippines', 'Sweden', 'Poland', 'Ukraine', 'Rome', 'Venezuela', 'Switzerland', 'Berlin', 'Bangladesh', 'Portugal', 'Ghana', 'Athens', 'king', 'Madrid', 'Somalia', 'Dublin', 'Qatar', 'Chile', 'Islamabad', 'Bahrain', 'Nepal', 'Norway', 'Serbia', 'Kabul', 'continent', 'Brussels', 'Belgium', 'Uganda', 'petroleum', 'Cairo', 'Denmark', 'Austria', 'Jamaica', 'Georgetown', 'Bangkok', 'Finland', 'Peru', 'Romania', 'Bulgaria', 'Hungary', 'Vienna', 'Kingston', 'Manila', 'Cyprus', 'Azerbaijan', 'Copenhagen', 'Fiji', 'Tunisia', 'Kazakhstan', 'queen', 'Beirut', 'Jakarta', 'Croatia', 'Belarus', 'Algeria', 'Malta', 'Morocco', 'Rwanda', 'Bahamas', 'Damascus', 'Ecuador', 'Angola', 'Canberra', 'Liberia', 'Honduras', 'Tripoli', 'Slovakia', 'Doha', 'Armenia', 'Taipei', 'Oman', 'Nairobi', 'Santiago', 'Guinea', 'Uruguay', 'Stockholm', 'Slovenia', 'Zambia', 'Havana', 'Uzbekistan', 'Belgrade', 'Mogadishu', 'Khartoum', 'Botswana', 'Kyrgyzstan', 'Dhaka', 'Namibia', 'Ankara', 'Abuja', 'Lima', 'Harare', 'Warsaw', 'Malawi', 'Lisbon', 'Latvia', 'Niger', 'Lithuania', 'Estonia', 'Samoa', 'Oslo', 'Nicaragua', 'Hanoi', 'Sofia', 'Macedonia', 'Senegal', 'Mozambique', 'Guyana', 'Mali', 'Accra', 'Kathmandu', 'Tbilisi', 'Helsinki', 'Montenegro', 'Caracas', 'Laos', 'Budapest', 'Kiev', 'Turkmenistan', 'Eritrea', 'Albania', 'Madagascar', 'Nassau', 'Kampala', 'Amman', 'Greenland', 'Belize', 'Moldova', 'Burundi', 'Tajikistan', 'Baku', 'Astana', 'Gambia', 'Bucharest', 'joyful', 'Monrovia', 'Mauritania', 'Algiers', 'Muscat', 'Bern', 'Luanda', 'Dakar', 'Tunis', 'Gabon', 'Minsk', 'Liechtenstein', 'Suva', 'Yerevan', 'Zagreb', 'Bishkek', 'Manama', 'Kigali', 'Riga', 'Lusaka', 'Tashkent', 'Nicosia', 'Valletta', 'Windhoek', 'Dominica', 'Quito', 'Tallinn', 'Bratislava', 'Tegucigalpa', 'Skopje', 'Gaborone', 'Rabat', 'Maputo', 'Suriname', 'Vilnius', 'Montevideo', 'Ljubljana', 'Tirana', 'Dushanbe', 'Ashgabat', 'Asmara', 'Tuvalu', 'Managua', 'Conakry', 'Banjul', 'Bamako', 'Lilongwe', 'Vientiane', 'Chisinau', 'Roseau', 'Nouakchott', 'Podgorica', 'Niamey', 'Bujumbura', 'Apia', 'Antananarivo', 'Libreville', 'Belmopan', 'Vaduz', 'Paramaribo', 'Nuuk', 'Funafuti'])
<class 'numpy.ndarray'>
countryVector:[-0.08007812 0.13378906 0.14355469 0.09472656 -0.04736328 -0.02355957
-0.00854492 -0.18652344 0.04589844 -0.08154297 -0.03442383 -0.11621094
0.21777344 -0.10351562 -0.06689453 0.15332031 -0.19335938 0.26367188
-0.13671875 -0.05566406 0.07470703 -0.00070953 0.09375 -0.14453125
0.04296875 -0.01916504 -0.22558594 -0.12695312 -0.0168457 0.05224609
0.0625 -0.1484375 -0.01965332 0.17578125 0.10644531 -0.04760742
-0.10253906 -0.28515625 0.10351562 0.20800781 -0.07617188 -0.04345703
0.08642578 0.08740234 0.11767578 0.20996094 -0.07275391 0.1640625
-0.01135254 0.0025177 0.05810547 -0.03222656 0.06884766 0.046875
0.10107422 0.02148438 -0.16210938 0.07128906 -0.16210938 0.05981445
0.05102539 -0.05566406 0.06787109 -0.03759766 0.04345703 -0.03173828
-0.03417969 -0.01116943 0.06201172 -0.08007812 -0.14941406 0.11914062
0.02575684 0.00302124 0.04711914 -0.17773438 0.04101562 0.05541992
0.00598145 0.03027344 -0.07666016 -0.109375 0.02832031 -0.10498047
0.0100708 -0.03149414 -0.22363281 -0.03125 -0.01147461 0.17285156
0.08056641 -0.10888672 -0.09570312 -0.21777344 -0.07910156 -0.10009766
0.06396484 -0.11962891 0.18652344 -0.02062988 -0.02172852 0.29296875
-0.00793457 0.0324707 -0.15136719 0.00227356 -0.03540039 -0.13378906
0.0546875 -0.03271484 -0.01855469 -0.10302734 -0.13378906 0.11425781
0.16699219 0.01361084 -0.02722168 -0.2109375 0.07177734 0.08691406
-0.09960938 0.01422119 -0.18261719 0.00741577 0.01965332 0.00738525
-0.03271484 -0.15234375 -0.26367188 -0.14746094 0.03320312 -0.03344727
-0.01000977 0.01855469 0.00183868 -0.10498047 0.09667969 0.07910156
0.11181641 0.13085938 -0.08740234 -0.1328125 0.05004883 0.19824219
0.0612793 0.16210938 0.06933594 0.01281738 0.01550293 0.01531982
0.11474609 0.02758789 0.13769531 -0.08349609 0.01123047 -0.20507812
-0.12988281 -0.16699219 0.20410156 -0.03588867 -0.10888672 0.0534668
0.15820312 -0.20410156 0.14648438 -0.11572266 0.01855469 -0.13574219
0.24121094 0.12304688 -0.14550781 0.17578125 0.11816406 -0.30859375
0.10888672 -0.22363281 0.19335938 -0.15722656 -0.07666016 -0.09082031
-0.19628906 -0.23144531 -0.09130859 -0.14160156 0.06347656 0.03344727
-0.03369141 0.06591797 0.06201172 0.3046875 0.16796875 -0.11035156
-0.03833008 -0.02563477 -0.09765625 0.04467773 -0.0534668 0.11621094
-0.15039062 -0.16308594 -0.15527344 0.04638672 0.11572266 -0.06640625
-0.04516602 0.02331543 -0.08105469 -0.0255127 -0.07714844 0.0016861
0.15820312 0.00994873 -0.06445312 0.15722656 -0.03112793 0.10644531
-0.140625 0.23535156 -0.11279297 0.16015625 0.00061798 -0.1484375
0.02307129 -0.109375 0.05444336 -0.14160156 0.11621094 0.03710938
0.14746094 -0.04199219 -0.01391602 -0.03881836 0.02783203 0.10205078
0.07470703 0.20898438 -0.04223633 -0.04150391 -0.00588989 -0.14941406
-0.04296875 -0.10107422 -0.06176758 0.09472656 0.22265625 -0.02307129
0.04858398 -0.15527344 -0.02282715 -0.04174805 0.16699219 -0.09423828
0.14453125 0.11132812 0.04223633 -0.16699219 0.10253906 0.16796875
0.12597656 -0.11865234 -0.0213623 -0.08056641 0.24316406 0.15527344
0.16503906 0.00854492 -0.12255859 0.08691406 -0.11914062 -0.02941895
0.08349609 -0.03100586 0.13964844 -0.05151367 0.00765991 -0.04443359
-0.04980469 -0.03222656 -0.00952148 -0.10888672 -0.10302734 -0.15722656
0.19335938 0.04858398 0.015625 -0.08105469 -0.11621094 -0.01989746
0.05737305 0.06103516 -0.14550781 0.06738281 -0.24414062 -0.07714844
0.04760742 -0.07519531 -0.14941406 -0.04418945 0.09716797 0.06738281]
提前写一个获取词向量的函数: 1
2def vec(w):
return word_embeddings[w]
2 在词向量上的操作
理解数据是数据科学的一个十分重要的步骤。词向量需要validated至少是被理解,因为它的质量对后面模型十分重要。
词向量是多维数组,通常拥有成百上千的属性,这也是对它解释的一个很大的挑战。
下面利用一对属性画出一些词的词向量,图中的点是对应的词,画出向量的箭头线能够比较方便地看出向量之间的夹角(夹角越近,两个词的意义越相近)。 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16words = ['oil', 'gas', 'happy', 'sad', 'city', 'town', 'village', 'country', 'continent', 'petroleum', 'joyful']
bag2d = np.array([vec(word) for word in words])
fig, ax = plt.subplots(figsize=(10, 10))
col1 = 3
col2 = 2
for word in bag2d:
ax.arrow(0, 0, word[col1], word[col2],
head_width=0.005, head_length=0.005,
fc='r', ec='r', width = 1e-5)
ax.scatter(bag2d[:, col1], bag2d[:, col2])
for i in range(0, len(words)):
ax.annotate(words[i], (bag2d[i, col1], bag2d[i, col2]))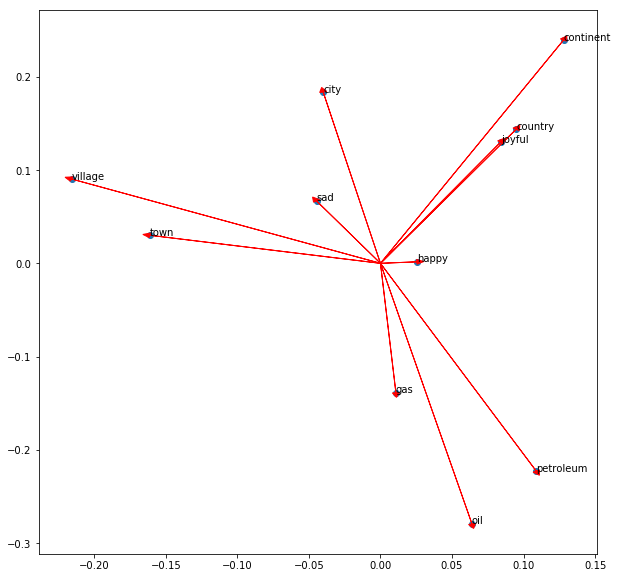
2.1 词间距离
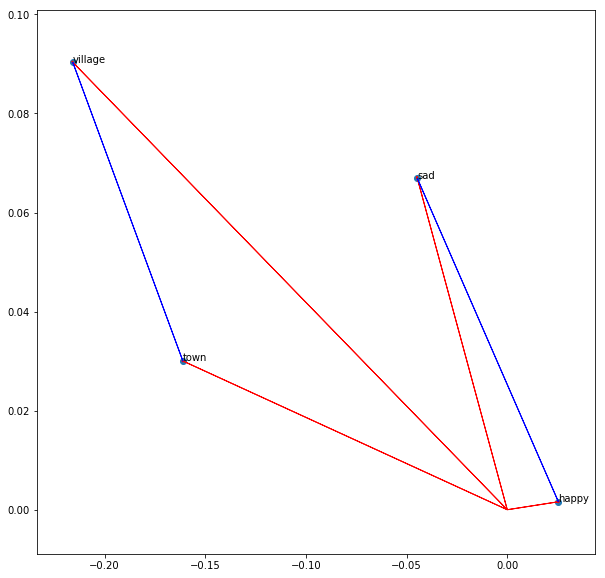
画出词 'sad', 'happy', 'town'以及'village',展示出从'village'指向'town'的向量以及从'sad'指向'happy'的向量。
1 | words = ['sad', 'happy', 'town', 'village'] |
2.2 通过操作词向量进行预测
现在利用向量减法和加法生成新的表示,举例来说,我们可以认为'France'和'Paris'的向量差可以表示首都。
现在来找那个国家的首都是'Madrid'。 1
2
3
4capital = vec('France') - vec('Paris')
country = vec('Madrid') + capital
print(country[0:10])[-0.02905273 -0.2475586 0.53952026 0.20581055 -0.14862823]
那么上面的词向量是预测的国家。其实按照常理我们知道'Madrid'是西班牙'Spain'的首都。现在来看一下两者的差值: 1
2diff = country - vec('Spain')
print(diff[0:10])[-0.06054688 -0.06494141 0.37643433 0.08129883 -0.13007355 -0.00952148 -0.03417969 -0.00708008 0.09790039 -0.01867676]
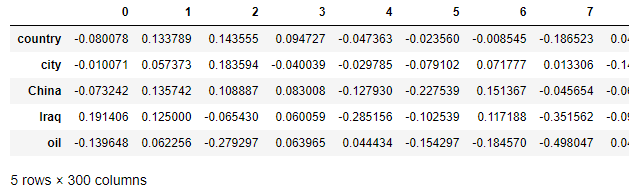
得到预测的向量后我们需要找到与它最接近的词。现在来写一个函数帮助找到已给向量最接近的词向量。(利用DataFrame来存储词向量,这样有利于查找)
1 | keys = word_embeddings.keys() |
1 | def find_closest_word(v, k=1): |
Spain
继续预测其他的国家: 1
2print(find_closest_word(vec('Brtlin')+capital))
print(find_closest_word(vec('Beijing')+capital))Germany China
有时也会预测出错: 1
print(find_closest_word(vec('Lisbon')+capital))
Lisbon
2.3 将句子表示为向量
一个句子可以通过对句子中所有词的词向量进行加和来表达。 1
2
3
4doc = "Spain petroleum city king"
vdoc = [vec(x) for x in doc.split(" ")]
doc2vec = np.sum(vdoc, axis = 0)
print(doc2vec)1
2
3
4
5
6
7
8
9
10
11
12
13
14array([ 2.87475586e-02, 1.03759766e-01, 1.32629395e-01, 3.33007812e-01,
-2.61230469e-02, -5.95703125e-01, -1.25976562e-01, -1.01306152e+00,
-2.18544006e-01, 6.60705566e-01, -2.58300781e-01, -2.09960938e-02,
-7.71484375e-02, -3.07128906e-01, -5.94726562e-01, 2.00561523e-01,
-1.04980469e-02, -1.10748291e-01, 4.82177734e-02, 6.38977051e-01,
2.36083984e-01, -2.69775391e-01, 3.90625000e-02, 4.16503906e-01,
2.83416748e-01, -7.25097656e-02, -3.12988281e-01, 1.05712891e-01,
3.22265625e-02, 2.38403320e-01, 3.88183594e-01, -7.51953125e-02,
-1.26281738e-01, 6.60644531e-01, -7.89794922e-01, -7.04345703e-02,
...
...
1.12304688e-02, -1.12060547e-01, -9.42382812e-02, 2.35595703e-02,
-3.92578125e-01, -7.12890625e-02, 5.69824219e-01, 9.81445312e-02],
dtype=float32)1
find_closest_word(doc2vec)
petroleum