《Glyce: Glyph-vectors for Chinese Character Representations》
Glyce:用于汉字表示的字形向量。
0 为什么要用汉字的字形?
因为对于类似汉字等等的象形文字来说,我们通常可以直接从字体的形状上来获取这个字的信息(对于我们早期的汉字来说--象形文字)。
1 Glyce简介:用于汉字表示的字形向量
对于类似汉字等等的象形文字来说,一般都会想要在NLP的各种任务中利用字体的形状上来获取这个字的信息。但是由于象形文字没有足够的丰富的证据再加上标准的计算机视觉模型在文字/字符上比较差的生成能力,所以亟待一种有效使用象形信息的方法。
论文《Glyce: Glyph-vectors for Chinese Character Representations》通过提出Glyce(Glyph-vectors for Chinese Character Representations)打破了这一僵住的局面。论文的主要创新点在于:
- 使用了各种历史汉字(例如:金文、篆书、繁体中文等等)来丰富文字中的象形信息。
- 为汉字图像处理专门设计了CNN结构(田字格-CNN)。
- 在多任务学习中使用图像分类作为副任务去提高模型的生成能力。
论文表示,在基于字/字符ID的模型的中文NLP任务中,比如标注任务(命名实体识别NER、中文分词CWS、词性标注POS),句子对分类任务,单一句子分分类任务,依存关系,都取得了当时的最优成绩。
Glyce模型及数据的GitHub:传送门
2 详细了解Glyce
从上一部分我们了解了Glyce的三大创新点,接着我们仔细了解下这三大创新点是什么样的?
2.1 使用各种历史文字
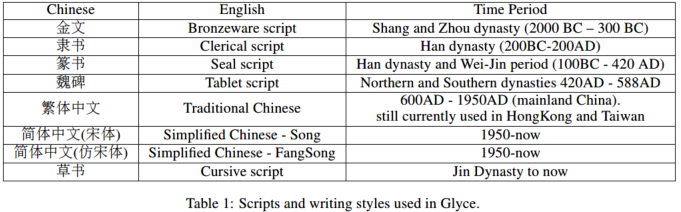
就是因为在简体中文中很多的图像上的信息都被严重丢失了,所以作者提出利用历史上不同时期、不同书写风格的字体。论文选取了主要的历史字体,如下图所示。不同的字体有着不同的形状,这可以帮助模型去整合不同来源的象形文字的信息,还能帮助模型提高模型的泛化能力。这种策略和计算机视觉中用到的数据增强策略是有共性的。
2.2 Glyce的田字格CNN
直接使用深度CNN模型在我们的任务中其实效果很差,因为
- 字形的图像相对是比较小的,一般来说CNN中用的是800 * 600,但是汉字的图像大小仅仅只有12 * 12。
- 训练数据的缺乏。一般对于图像分类来说,像ImageNet数据集,可能有数千万张图像,但是对于汉字来说仅仅有10000个。
为了解决上述问题,作者提出了田字格CNN架构,如下图所示,这个模型就是为了汉字而设计的。 
输入图像\(x_image\)首先经过了核大小为5的卷积层,然后输出channel为1024(为了捕获低层的图形特征)。接着将上面输出的特征图feature map通过一个核大小为4的最大池化层,feature map的大小就从8 * 8变成了2 * 2。这个2 * 2的田字格结构代表了在汉字中部首偏旁是怎么组织起来的,同时也代表了写下的是哪一个汉字。最后,作者使用了分组卷积(关于分组卷积下面有补充说明)来生成最后的输出。分组卷积核比普通卷积核小得多,因此不太容易过度拟合。其实,将模型从单一字体调整为多字体是很简单的,也就是因需要将原来2D的输入:\(d_font \times d_font\)变为3D的输入:\(d_font \times d_font \times N_script\)。这里面,\(d_font\)是指字体(图像)大小,\(N_script\)是指使用的字体的数量。
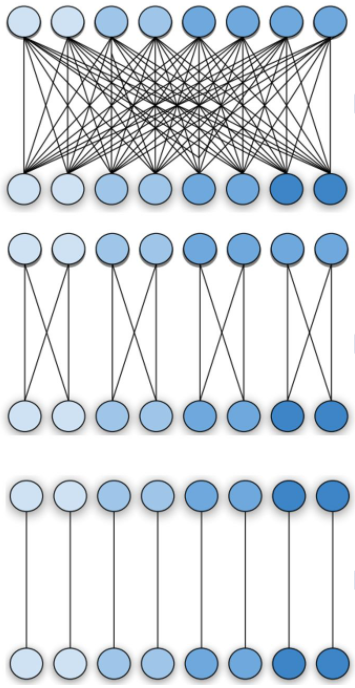
补充分组卷积:传统的卷积操作是每一个输出的channel都与输入的每一个channel相连接(稠密的)。分组卷积(group convolution)中输入和输出的channel被分为一个个组,每个组的输出channel只和对应组内的输入channel相连接,与其他channel无关。下面的图就是传统卷积和不同的分组卷积示意: