集成学习之Bagging
0 关于集成学习要说的事
0.1 什么是集成学习?
集成学习(Ensemble Learning)通过构建并结合多个学习器来完成学习任务。
集成学习的一般结构是:先产生一组“个体学习器”,再用某种策略将它们结合起来。个体学习器通常由一个现有的学习算法从训练数据产生,可以是决策树、BP神经网络等。
同质集成与异质集成:如果在集成的时候用到的个体学习器都是一样类型的,那么这样的集成是“同质”的;如果个体学习器存在不同的类型,那么这样的集成就是“异质”的。
0.2 集成学习怎么才能获得好的结果?
集成学习把多个学习器结合起来,如何能获得比最好的单一学习器更好的性能呢?
考虑一个简单的例子:在二分类任务中,假定有三个分类器在三个测试样本上的表现如下图所示,根据投票法(少数服从多数)产生集成后的结果。图中对号代表分类正确,叉号代表分类错误。那么,分析可知不同分类器需要好而不同才能达到提升效果的作用,也就是需要各个分类器都有不错的分类效果同时它们还要有差异(多样性--否则集成就没有什么提升的作用了)。但其实个体学习器的“准确性”和“多样性”本身是存在冲突的,如何做到“好而不同”恰恰是集成学习研究的核心。 
0.3 集成学习方法的分类
目前,集成学习大致可以分为Bagging、Boosting、Stacking。
先简单来看这三种类型的集成学习是什么样的,后面再分开仔细学习。
- Bagging
Bagging是指每个基学习器进行有放回抽样得到子训练集,然后每个基学习器基于其训练集进行训练,最后综合所有基学习器的预测值得到最终的预测结果。(这里综合的方法常常是投票法,票数最多的类别作为最终的预测类别。)整个训练和测试过程如下图所示: 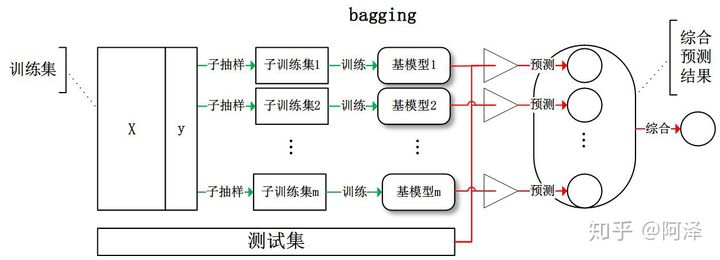
- Boosting
Boosting是指每个基学习器在前一个基学习器的基础上进行学习,最后综合所有基学习器的预测值产生最终的预测结果。(这里综合的方法常常是加权法。)整个训练和测试过程如下图所示: 
- Stacking
Stacking是先用全部数据训练好各个基学习器,然后基学习器对每个训练样本的预测值作为新的训练样本的特征值(相当于x',真实值作为这里x'的y---标签不变,然后这个新的训练样本在一个模型上进行训练得到的预测值为最终的预测结果。也就是说原来的投票法、加权法等等方式变成了利用一个模型来学习得出最后的结果。整个训练和测试过程如下图所示: 
1 什么是Bagging?
上一部分给出了Bagging的简单描述,这里来更详细地了解它。
首先,在一开始我们知道了集成学习需要“好而不同”的模型,在Bagging这种类型的集成学习方法中,通过自助采样(bootstrap)或者叫有放回抽样得到不同的子训练集,然后个体学习器基于不同的子训练集进行训练。这样的考虑是为了通过采样得到的子训练集的不同来增加各个个体学习器之间的差异性。
自助采样或者有放回抽样的具体实现是,假设我们拥有训练集X,首选随机取出一个样本放入采样集合\(X_sub\)中,再把这个样本放回训练集X,重复K次采样,最终获取到了一个大小为K的子训练集\(X_sub\)。重复上面的抽样N次,就可以得到T个子训练集。这T个子训练集分别投喂到不同的个体学习器中训练,最后将它们结合得到最后的结果。如果问题属于回归问题,那么最后的结合是指将各个个体学习器的结果求平均值;如果问题属于分类问题,那么最后的结合是指对各个个体学习器的结果进行投票(少数服从多数)。 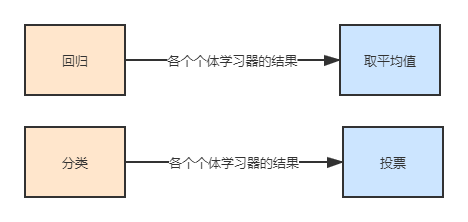
2 投票法
在Bagging的过程中最后用到了投票法进行最后结果的选择,如上一部分所示。对于回归模型来说,投票法最终的预测结果是多个其他回归模型预测结果的平均值。对于分类模型,硬投票法的预测结果是多个模型预测结果中出现次数最多的类别,软投票对各类预测结果的概率进行求和,最终选取概率之和最大的类标签。
关于硬投票和软投票,它们可能对同一任务得到不同的结果。因为相对于硬投票来说,软投票考虑到了预测概率这一额外的信息,因此可以得出比硬投票更加准确的预测结果。
3 基于sklearn的Bagging案例分析
在sklearn中基于Bagging方法的有BaggingRegressor和BaggingClassifier。下面是使用sklearn来实现基于决策树进行分类的Bagging,也就是说上面所述的个体学习器为决策树。
首先创建含有1000个样本的随机分类数据集,每个样本应有20维的特征。
输出:1
2
3
4
5from sklearn.datasets import make_classification
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=5)
print(X, y)(1000, 20) (1000,)使用重复的分层k-fold交叉验证来评估
BaggingClassifier(),一共重复三次,每次有10个fold。
1 | from numpy import mean |
输出:Accuracy is 0.859 , the standard deviation of accuracy is 0.032
其中,在cross_val_score函数中,scoring代表调用方法(包括accuracy和mean_squared_error等等),cv代表交叉验证参数,n_jobs用于设置同时工作的cpu个数(-1代表全部),error_score表示 如果在估计器拟合中发生错误,要分配给该分数的值(一般不需要指定,默认为raise,它表示在模型拟合过程如果产生误差,在raise情况下,误差分数将会提高)。
参考
西瓜书
阿泽知乎传动门