数据分析之数据清洗与特征处理
1 数据清洗
通常我们得到的数据需要清洗,即对数据中的缺失值、异常值等进行一定的处理,再进行字符串和数据转换等操作。在数据清洗完成后再进行分析或建模。
pandas使用浮点值NaN(Not a Number)表示缺失数据,称其为哨兵值。在进行浮点值判断时会有一些陷阱,参考博客:pandas中对nan空值的判断和陷阱。
1.1 缺失值的观察和处理
通常拿到的数据会有很多缺失值,比如上篇中我们用的泰坦尼克号数据集中Cabin列存在NaN,那其他列还有没有缺失值?这些缺失值要怎么处理呢?
首先导入工具包和数据: 1
2
3
4import numpy as np
import pandas as pd
train_data = pd.read_csv('train.csv')
查看每个特征缺失值个数如下,根据输出发现Age,Cabin,Embarked列出现缺失值。
1 | ## 方式一 |
输出: 
1 | ## 方式二 |
输出: 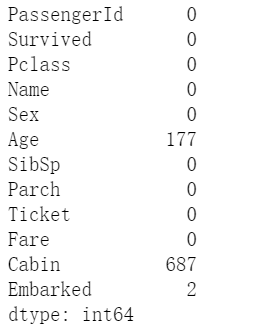
查看Age,Cabin,Embarked列的数据。
1 | train_data[["Age","Cabin","Embarked"]].head(10) |
输出: 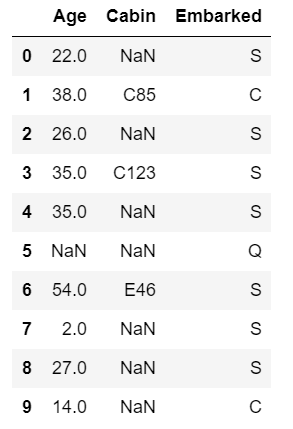
- b.对缺失值进行处理
对缺失数据的处理包括滤除缺失数据、填充缺失数据。
滤除缺失数据可以通过isnull函数等手工方式,或者直接利用dropna函数。对于一个Series,dropna返回一个仅含非空数据和索引值的Series;对于DataFrame对象,你可能希望丢弃全NA或含有NA的行或列,dropna默认丢弃任何含有缺失值的行: 1
train_data.dropna().head(10)
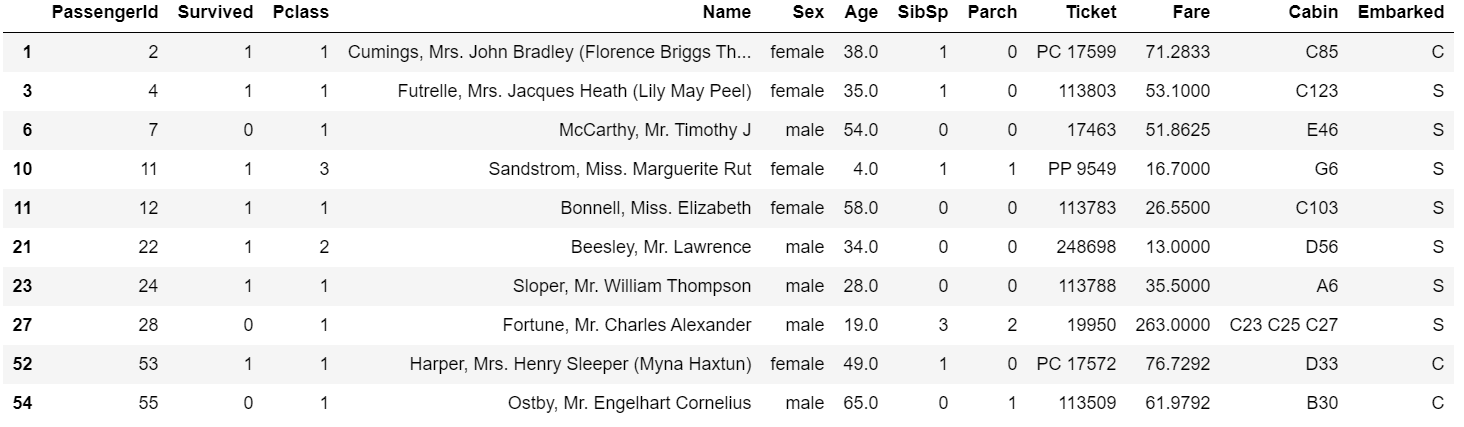
更多的关于
dropna函数的参数和使用等等的内容参考:传送门
填充缺失数据可以通过isnull函数等手工方式,或者直接利用fillna函数。你可能不想滤除缺失数据(有可能会丢弃跟它有关的其他数据),而是希望通过其他方式填补那些“空洞”。对于大多数情况而言,fillna方法是最主要的函数。
通过fillna传入常数就会将缺失值替换为那个常数值。 1
train_data.fillna(0).head(10)
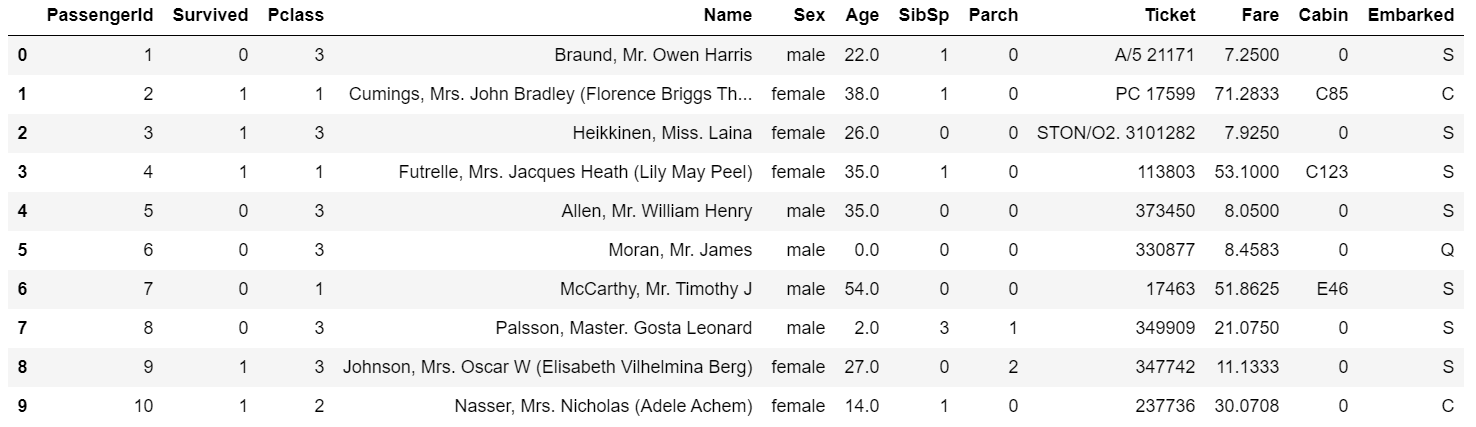
如果通过一个字典调用fillna就可以实现对不同的列填充不同的值: 1
train_data.fillna({'Age':0, 'Cabin':'No'}).head(10)
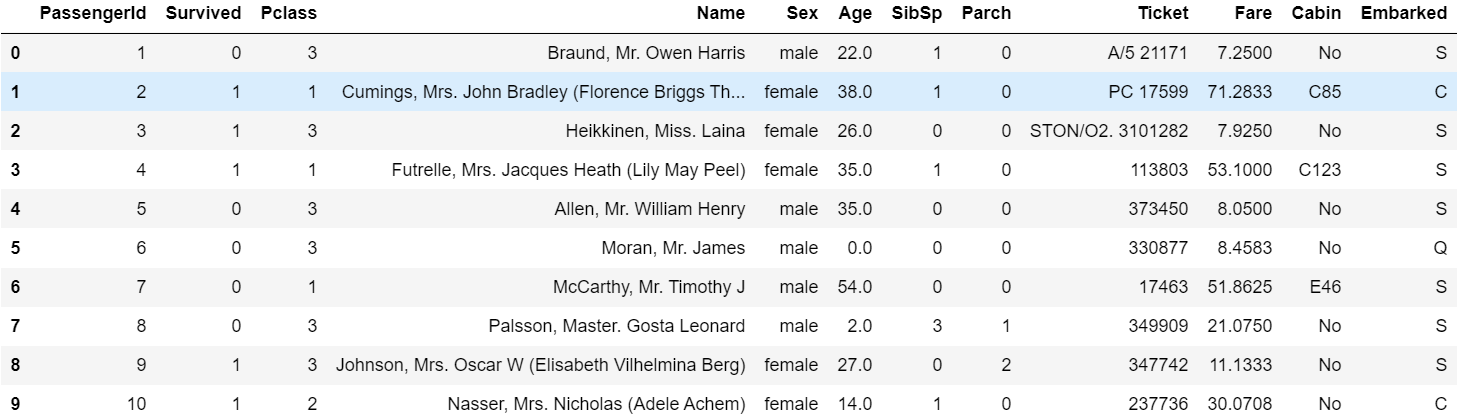
fillna默认会返回新对象,但也可以对现有对象进行就地修改,只要参数中设置inplace=True即可。
1.2 重复值的观察与处理
可能由于一些原因数据中会出现重复值,所以对数据进行清洗的时候需要进行重复值的处理。
- a.观察重复值
DataFrame的duplicated方法返回一个布尔型Series,表示各行是否是重复行(前面出现过的行)。 1
2
3train_data.duplicated()
##下面这种方式直接将重复的行展示出来
train_data[train_data.duplicated()]
利用drop_duplicates方法进行整行重复的数据进行删除,它会返回一个DataFrame。
1 | df.drop_duplicates().head() |
对清洗后的数据进行保存可以用to_csv函数,确保是清洗后新的数据对象或者操作时函数设置了inplace参数(即确保是修改后的数据。)
2 特征处理
对特征进行一下观察,可以大概分为两大类:
- 数值型特征:Survived ,Pclass, Age ,SibSp, Parch, Fare。其中Survived, Pclass为离散型数值特征;Age,SibSp, Parch, Fare为连续型数值特征。
- 文本型特征:Name, Sex, Cabin,Embarked, Ticket。其中Sex, Cabin, Embarked, Ticket为类别型文本特征。
数值型特征一般可以直接用于模型的训练,但有时候为了模型的稳定性及鲁棒性会对连续变量进行离散化。文本型特征往往需要转换成数值型特征才能用于建模分析。
2.1 对年龄进行离散化处理(分箱)
1 | #方式一:将连续变量Age平均分箱成5个年龄段,并分别用类别变量12345表示 |
输出: 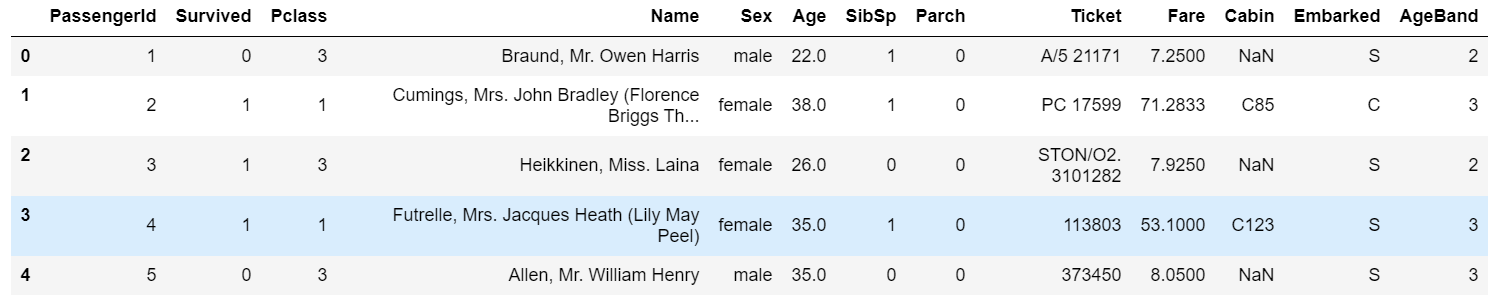
1 | #方式二:将连续变量Age划分为[0,5) [5,15) [15,30) [30,50) [50,80)五个年龄段,并分别用类别变量12345表示 |
输出: 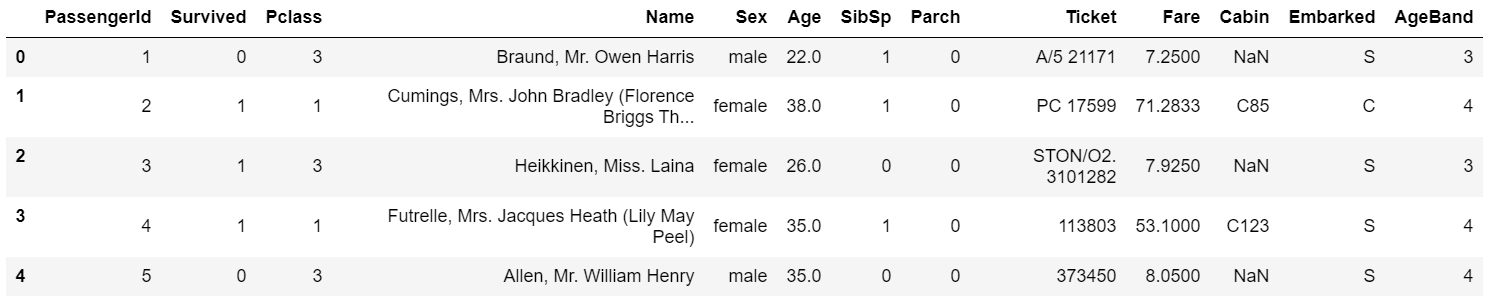
1 | #方式三:将连续变量Age按10% 30% 50 70% 90%五个年龄段,并用分类变量12345表示 |
输出: 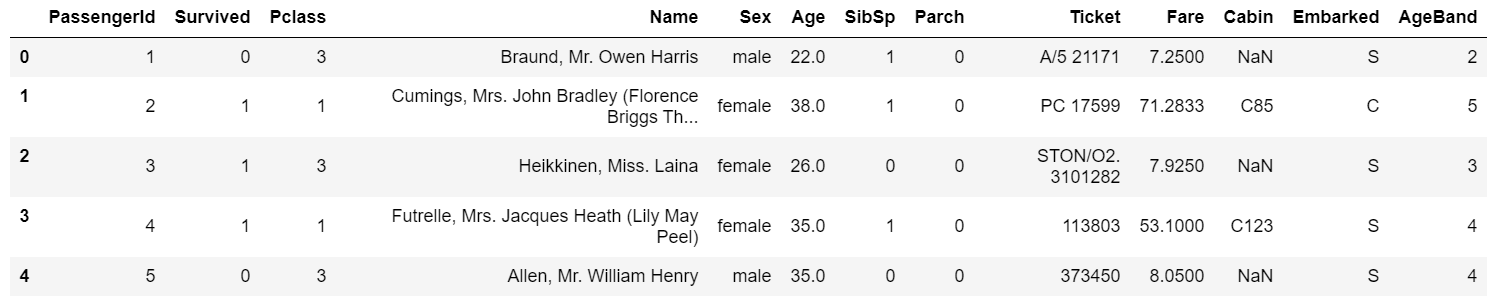
2.2 对文本变量进行转换
查看文本变量对应的不同的值是什么:
1 | train_data['Sex'].unique() |
输出:array(['male', 'female'], dtype=object)
文本变量对应的不同的值的个数:
1 | train_data['Sex'].nunique() |
输出:2
并将不同的变量值映射为不同的数值:
1 | #方法一: replace |
输出: 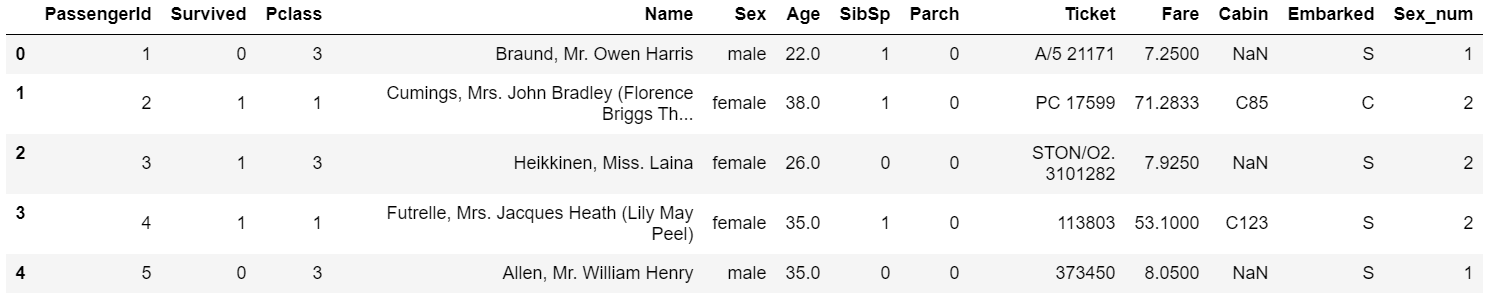
1 | #方法二: 使用sklearn.preprocessing的LabelEncoder |
输出: 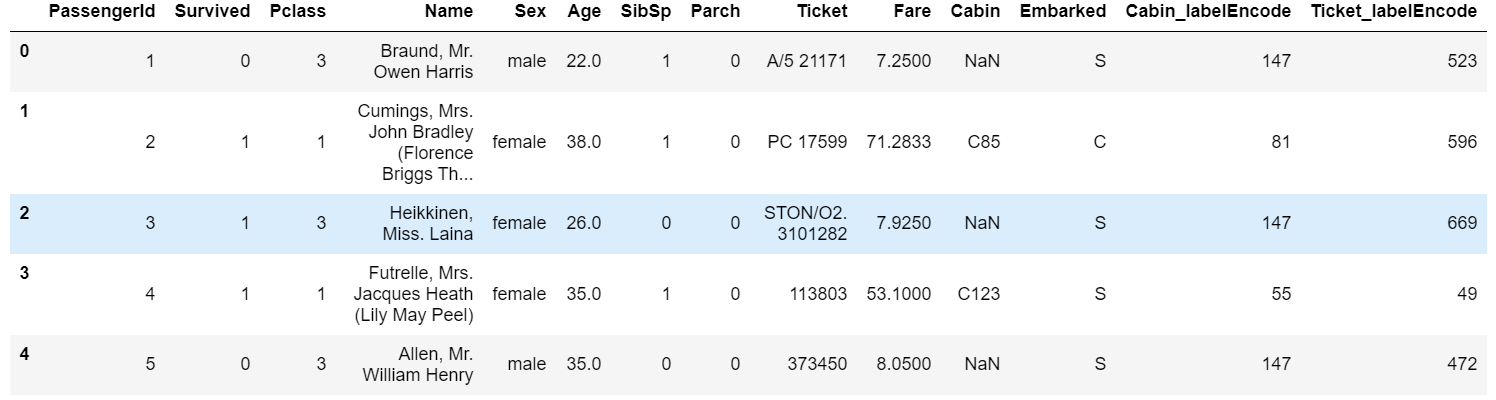
2.3 从Name特征中的文本里提取提取出Titles的特征(所谓的Titles就是Mr,Miss,Mrs等)
1 | train_data['Title'] = train_data['Name'].str.extract('([A-Za-z]+)\.', expand=False) |
输出: 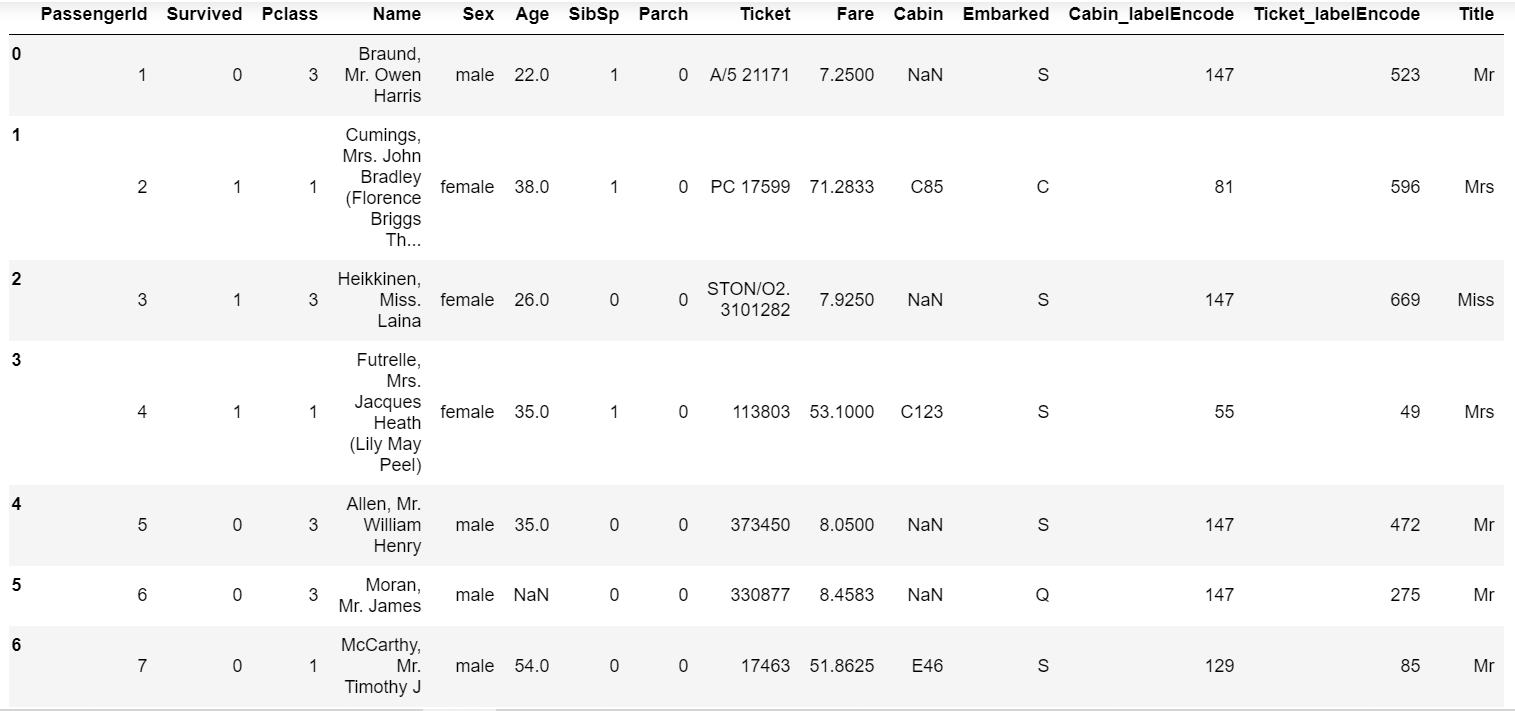
如果上述特征需要保存,可以利用
to_csv函数进行保存。
3 数据重构
有的时候需要对数据进行横向或者纵向的连接,这个时候可以使用如下的方法:
数据库风格的DataFrame
merge 或 join