字符串
收录字符的相关编程。
1 打印一个字符串全部子序列,包括空字符串
python实现如下:
1 | ## 给定字符串s,找出它所有的子序列 |
求出最长公共子序列,在dp数组的遍历方式可以参考下面的图: 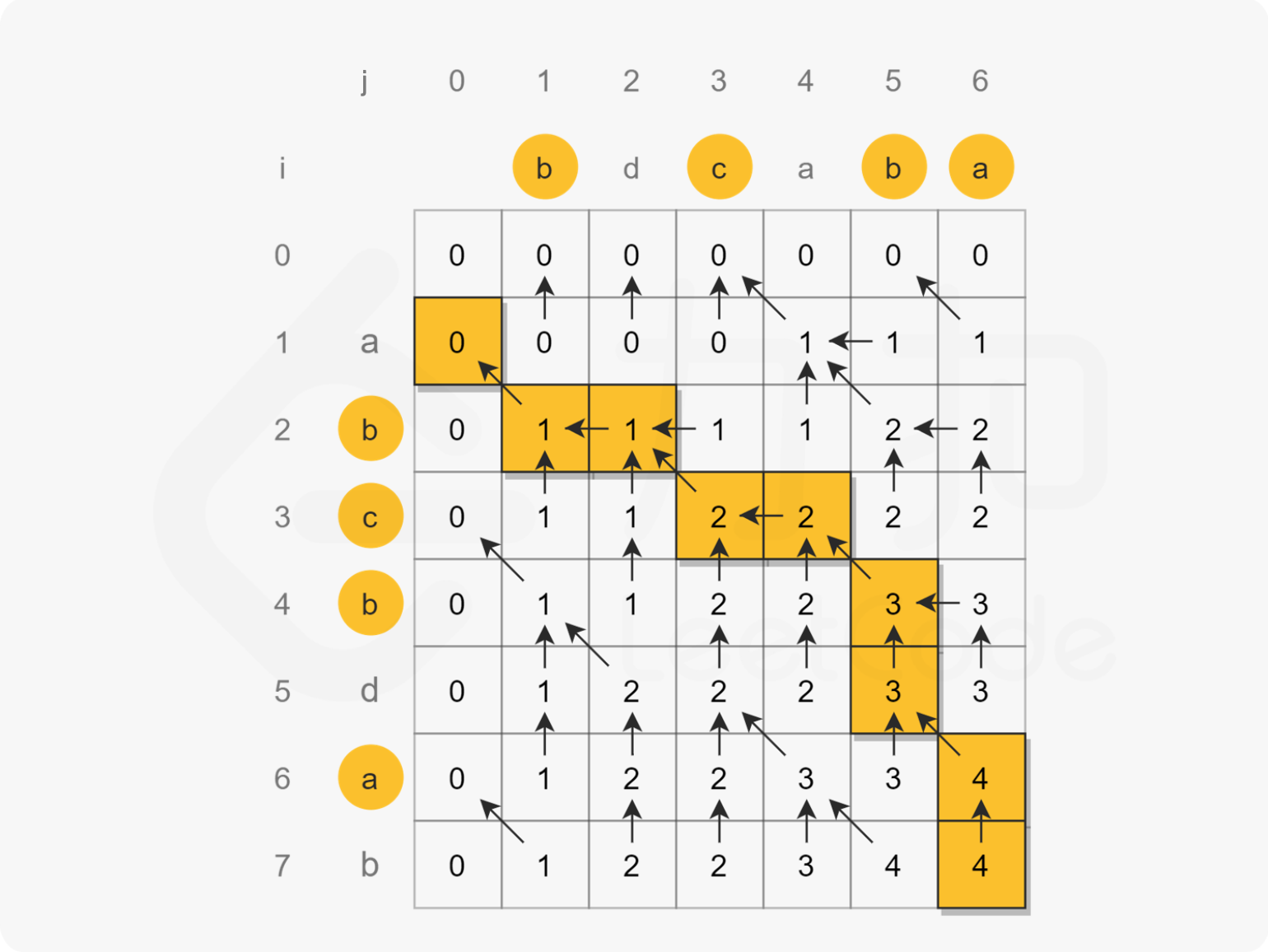
要是求两个字符串的公共子串,代码实现如下:
1 | def longestCommonSubsting(text1: str, text2: str) -> int: |
3 字符串的所有排列组合
给定一个字符串,找出所有的其中字符的组合。
python实现: ## 4 KMP——判断一个字符串是否为另一字符串的子串1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21## 求所有的字符组合
def all_permutation(s, i, result):
if i == len(s):
result.append(''.join(s))
return
for j in range(i, len(s)):
swap(s, i, j)
all_permutation(s[:], i+1, result)
swap(s, i, j)
def swap(s, i, j):
tmp = s[i]
s[i] = s[j]
s[j] = tmp
## 测试
result= []
s = 'abc'
s = list(s)
all_permutation(s, 0, result)
print(result)
KMP算法是对暴力匹配的一种优化/提升。
1 | def get_next_array(str_target): |