知识图谱
0 知识图谱考古
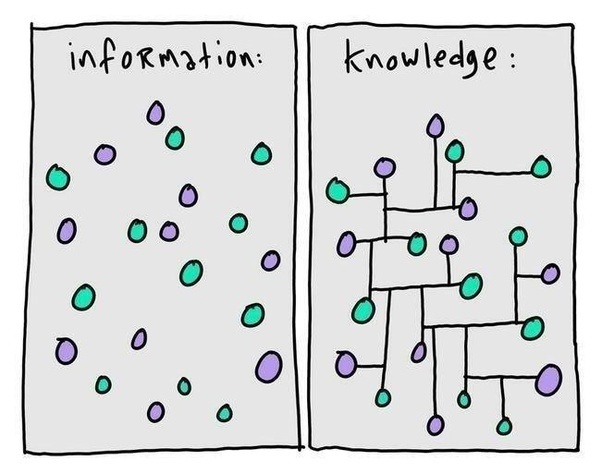 2012年,Google正式提出了知识图谱(Knowledge Graph, KG)的概念,初衷是为了优化搜索引擎返回的结果,增强用户搜索质量和体验。搜索引擎有知识图谱作为辅助,能够洞察用户查询信息背后的语义信息。Google知识图谱的宣传语“things not strings”给出了知识图谱的精髓,即不要无意义的字符串而是获取字符串背后隐含的对象或事物。
2012年,Google正式提出了知识图谱(Knowledge Graph, KG)的概念,初衷是为了优化搜索引擎返回的结果,增强用户搜索质量和体验。搜索引擎有知识图谱作为辅助,能够洞察用户查询信息背后的语义信息。Google知识图谱的宣传语“things not strings”给出了知识图谱的精髓,即不要无意义的字符串而是获取字符串背后隐含的对象或事物。
看到的不仅仅是文本
对于人类来说,\({\color{Plum}{罗纳尔多}}\)四个字代表着有一个球星:罗纳尔多·路易斯·纳萨里奥·德·利马,他是巴西人,身高180体重98公斤等等。但是对于机器来说,\({\color{Plum}{罗纳尔多}}\)仅仅是字符串。为了让机器能够知道文本背后的含义,我们需要对\({\color{Plum}{罗纳尔多}}\)这个实体进行建模,填充它的属性并拓展它和其他事物的联系,知识图如下所示。 
其实,知识图谱的背后思想可以追溯到上个世纪五六十年代的一种知识表现形式——语义网络(Semantic Network)。 语义网络由相互连接的节点和边组成,如下图所示,节点表示概念或者对象,边表示概念或者对象之间的关系(is-a关系,比如:猫是一种哺乳动物;part-of关系,比如:脊椎是哺乳动物的一部分))。 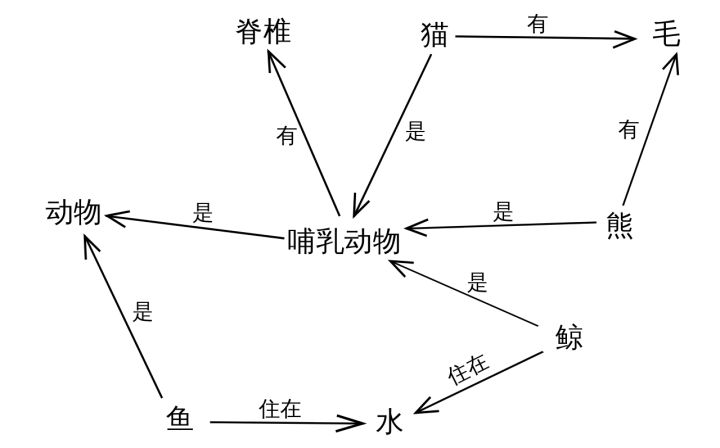
知识图谱和语义网络看起来很像,但是语义网络更侧重于描述概念和概念之间的关系,而知识图谱更侧重于描述实体之间的关联。
1 什么是知识图谱
知识图谱(没有一个标准的定义)可以被描述为它是由一些相互连接的实体和它们的属性构成的。(此处为一种理解方式,另外一种见后面第3小节)可以理解为知识图谱是由一条条知识组成,每条知识表示为SPO(Subject-Predicate-Object, 主-谓-宾)三元组: 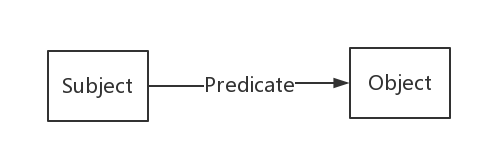
补充:在知识图谱中,用RDF形式化地表示这种三元关系。RDF(Resource Description Framework),即资源描述框架,是W3C制定的,用于描述实体/资源的标准数据模型。RDF图中一共有三种类型,International Resource Identifiers(IRIs,可以看做是URI或者URL的泛化和推广,它在整个网络或者图中唯一定义了一个实体/资源,和我们的身份证号类似。),blank nodes 和 literals(纯文本)。
下面是SPO每个部分的类型约束: * Subject可以是IRI或blank node。 * Predicate是IRI。 * Object三种类型都可以。
在知识图谱,用RDF图表示“罗纳尔多的中文名是罗纳尔多·路易斯·纳扎里奥·达·利马”的三元组(S(罗纳尔多)-P(中文名是)-O(罗纳尔多·路易斯·纳扎里奥·达·利马)): 
www.kg.com/person/1是一个IRI,用来唯一的表示“罗纳尔多”这个实体。 "kg:chineseName"也是一个IRI,用来表示“中文名”这样一个属性。"kg:"是RDF文件中所定义的prefix,如下所示。 @prefix kg: http://www.kg.com/ontology/kg:chineseName其实就是"http:// www.kg.com/ontology/chineseName"的缩写。
将上面罗纳尔多的知识图表示为知识图谱的RDF形式为: 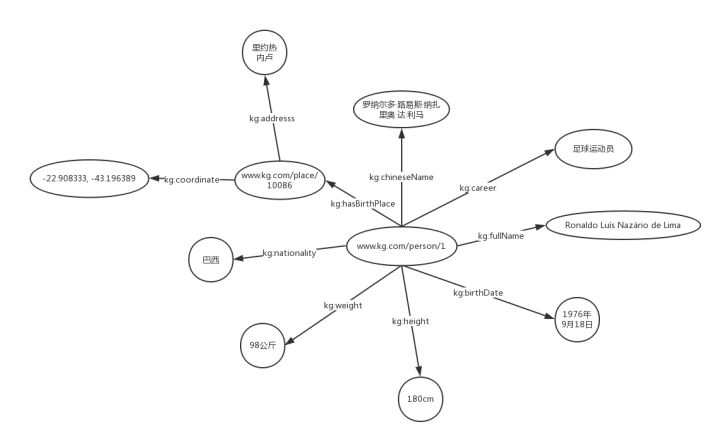
2 知识图谱的数据类型和存储方式
数据类型
知识图谱的原始数据类型一般来说有: 1. 结构化数据,如关系数据库 3. 半结构化数据,如XML、JSOM、百科 2. 非结构化数据,如图片、音频、视频
上述数据类型也是互联网上的三类原始数据。
存储方式
通过上面知识图谱的介绍能够了解到其内涵,其实知识图谱不只有RDF,还可以基于图数据库。
部分参考:链接
基于图数据库的知识图谱
基于图数据库的知识图谱看起来是: 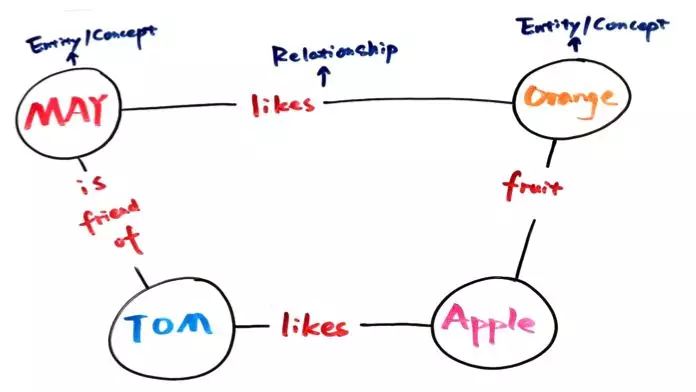
如果两个节点之间存在关系,它们就会被一条无向边连接在一起。节点称为实体(Entity),它们之间的这条边,就称为关系(Relationship)。基于图数据库的知识图谱的基本单位便是“实体(Entity-关系(Relationship-实体(Entity)”构成的三元组。
RDF与图数据库的对比
\({\color{purplr}{RDF}}\)一个重要的设计原则是数据的易发布以及共享,\({\color{purplr}{图数据库}}\)则把重点放在了高效的图查询和搜索上。
\({\color{purplr}{RDF}}\)以三元组的方式来存储数据而且不包含属性信息,但\({\color{purplr}{图数据库}}\)一般以属性图为基本的表示形式,所以实体和关系可以包含属性,这就意味着更容易表达现实的业务场景。
\({\color{purplr}{RDF}}\)多用于学术界,\({\color{purplr}{图数据库}}\)多用于工业界。
实现工具
Neo4j系统目前仍是使用率最高的图数据库,它拥有活跃的社区,而且系统本身的查询效率高,但唯一的不足就是不支持准分布式: 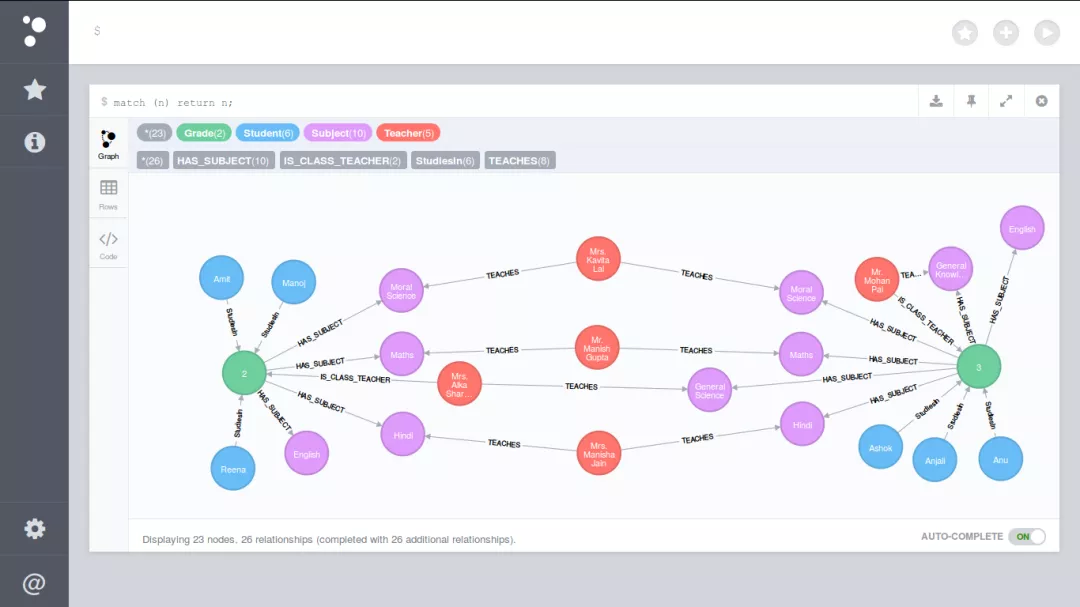
相反,OrientDB和JanusGraph(原Titan)支持分布式,但这些系统相对较新,社区不如Neo4j活跃,这也就意味着使用过程当中不可避免地会遇到一些刺手的问题。
如果选择使用RDF的存储系统,Jena或许是一个比较不错的选择。 
后面含有为基于图数据库的Neo4J工具进行的知识图谱构建,关于RDF的Jena工具的知识图谱构建可以参考从零开始构建知识图谱。
3 知识图谱的架构
参考链接:传送门
知识图谱的架构主要被分为两部分: 1. 逻辑架构 2. 技术架构
a. 逻辑架构
在逻辑上,通常将知识图谱划分为两个层次:
数据层:存储真实数据。
模式层:在数据层之上,为知识图谱的核心,存储经过提炼的知识,通常通过本体库(可以理解为面向对象里的“类”这样一个概念,本体库就储存这知识图谱的类。)来管理这一层。
举例来说:
数据层:比尔盖茨-妻子-梅琳达·盖茨,比尔盖茨-总裁-微软
模式层:实体-关系-实体,实体-属性-属性值
b. 技术架构
知识图谱的整体架构如下图所示: 
虚线框内为知识图谱的构建过程,同时也是知识图谱的更新过程。总结上图为:首先我们有一大堆数据,这些数据可能是结构化的、非结构化的以及半结构化的,然后基于这些数据来‘构建知识图谱’(见下面),这一步主要通过一系列自动化或半自动化的技术手段来从原始数据中提取出知识要素(即一堆实体关系),并将其存入知识库的模式层和数据层。
构建知识图谱
构建知识图谱是一个迭代更新,根据知识获取的逻辑,每一轮迭代包含三个大阶段:
I 信息抽取
信息抽取:从各种类型的数据源中提取出实体、属性以及实体间的相互关系,在此基础上形成本体化(类)的知识表达。
信息抽取是一种自动化地从半结构化和无结构数据中抽取实体、关系以及实体属性等结构化信息地技术。它主要包含:实体抽取、关系抽取和属性抽取。
a 实体抽取
实体抽取也成为命名实体识别(Named Entity Recognition,NER),是指从文本数据集中自动识别出命名实体。
举例,下面的文本中抽取出了"Steve Balmer", "Bill Gates"和"Microsoft"三个命名实体。 命名实体识别是一种相对比较成熟的技术。 
b 关系抽取
文本语料经过实体抽取之后得到了一系列离散的命名实体,为了得到语义信息,需要提取出实体之间的关系,这样就能形成网状的知识结构。
举例: 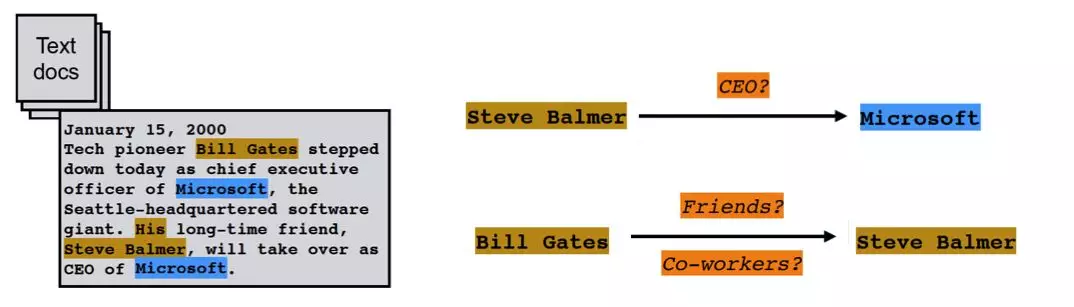
c 属性抽取
属性抽取的目标是从不同的信息源中采集特定实体的属性信息,比如针对某个公众人物,可以从网络公开信息中得到其生日、国籍、教育背景等等。
II 知识融合
知识融合:在获得新知识后,需要对其进行整合,来消除矛盾和歧义。比如,某些实体可能有多种表达,某个特定称谓也许对应多个不同的实体。
经过信息抽取得到实体、关系以及实体的属性信息后,需要正确地将抽取到的实体对象链接到知识库中对应的正确实体对象,这称为实体链接,它包括实体统一(对应Entity Resolution或者说Entity Disambiguation)和指代消歧(Disambiguation或者说Coreference Resolution)。
实体统一:对于有些实体写法上不一样,但其实是指同一个实体的情况进行统一。比如下图中
NYC和New York写法上不一致,但是它们共同指向的都是纽约这个城市,需要合并。这里主要用到的技术是聚类法,也可以是基于上下文的分类。
指代消解:对于代词的指向的确定。比如下图中
it,he,she这个代词到底指向哪个实体需要明确。

参考链接:Datawhale 知识图谱组队学习 之 Task 1 知识图谱介绍
III 知识加工
知识加工:对于经过融合的新知识,需要经过质量评估(可能需要人工参与)之后才能将合格的部分加入到知识库,以确保知识库的质量。
上面的过程已经完成了信息的抽取,从原始语料中提取出了实体、关系和属性等知识要素,经过知识融合消除了实体歧义的问题,得到一系列基本事实的表达。但是,事实不等于知识,想要获得结构化、网络化的知识体系需要再通过知识加工。知识加工包括:本体构建、知识推理和质量评估。
a 本体构建
本体(ontology)(可以看做知识图谱的schema)是指一种概念框架(或者说知识结构),学术定义是:一个由实体< 类别、个体、关系、数据类型、数值> 以及它们的关系<子类关系、正交关系、实例关系、等价关系> 组成的集合。
本体的构建一般都是自动化本体构建(人工的方式工作量太大),自动化本体构建过程包括:1-实体并列关系相似度计算,2-实体上下位关系抽取,3-本体的生成。
举例来说, 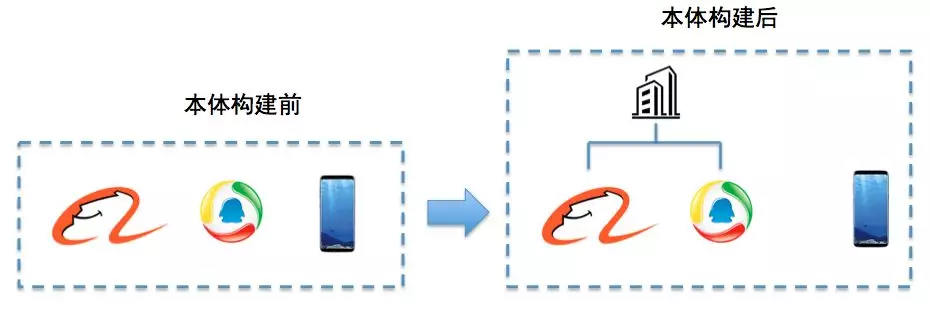
当知识图谱刚得到上图中的“阿里巴巴”、“腾讯”、“手机”这三个实体时可能会认为它们三个之间并没有什么差别,但当它去计算三个实体之间的相似度后,就能得到“阿里巴巴”和“腾讯”可能更相似,和“手机”差别更大。这是第一步。接着,知识图谱需要得到一个上下层的概念,就像“阿里巴巴”“腾讯”可能属于同一类型,它们与“手机”就不隶属于一个类型。所以实体上下文关系抽取就需要完成上述任务,从而生成本体(最后一步)。
经过本体构建,知识图谱可能就会知道“阿里巴巴和腾讯,其实都是公司这样一个实体下的细分实体。它们和手机并不是一类。”
b 知识推理
完成本体构建后,知识图谱的雏形便完成了。在雏形阶段,知识图谱之间的大多数关系都是残缺的(缺的还挺厉害),这个时候就需要使用知识推理技术去进一步完善知识图谱。
举例来说: 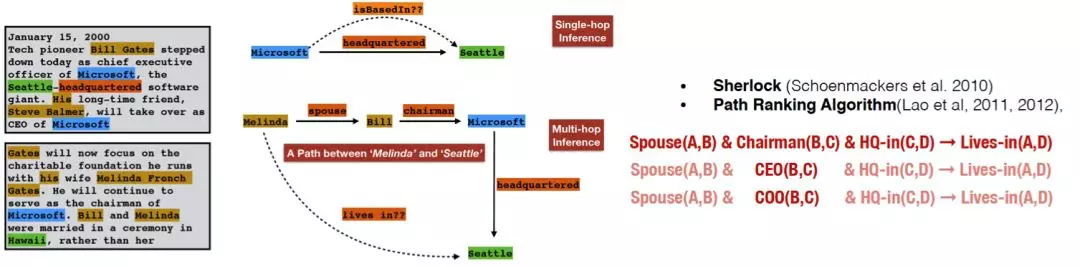
仔细观察可以发现,A是B的配偶,B是C的主席(或者CEO,或者COO),C坐落于D,那么我们就可以认为,A生活在D这个城市。根据这一条规则就可以去挖掘一下在图里,是不是还有其他的path满足这个条件,那么我们就可以将AD两个关联起来。
知识推理的对象也并不局限于实体间的关系,也可以是实体的属性值、本体的概念层次关系等,举例如下:
- 推理属性:已知某实体的生日属性,可以通过推理得到该实体的年龄属性。
- 推理概念:已知某实体的生日属性,可以通过推理得到该实体的年龄属性。
推理的技术主要包括:基于逻辑的推理、基于图的推理和基于深度学习的推理。
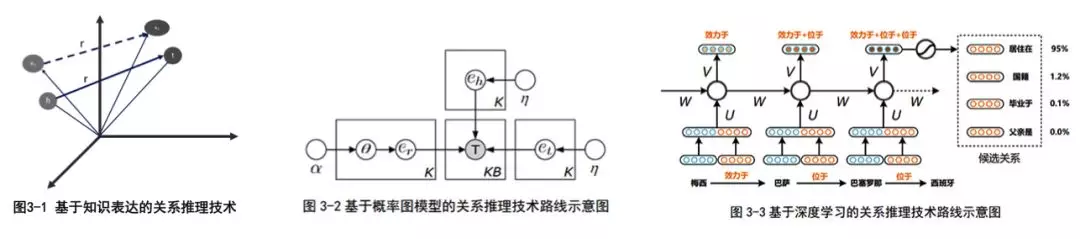
c 质量评估
这一步是对知识的可信度进行量化,通过舍弃置信度低的知识来保证知识图谱的质量。
知识更新
从逻辑上看,知识库的更新包括数据层的更新和模式层的更新:
数据层的更新主要是新增或更新实体、关系、属性值。对数据层进行更新需要考虑数据源的可靠性、数据的一致性(是否存在矛矛盾或冗余等问题),并选择在各类数据源中出现频率高的事实和属性加入知识库。
模式层的更新是指新增数据后获得了新的概念,需要自动将新的概念添加到知识库的模式层中。
4 基于图数据库的知识图谱实现
工具之Neo4J
a. 下载
下载链接:Neo4J(快) Neo4J官网(慢...)
可以直接下载Desktop版,比较好直接上手。
关于操作,移步这里
最终的知识图谱(自己创建)为: 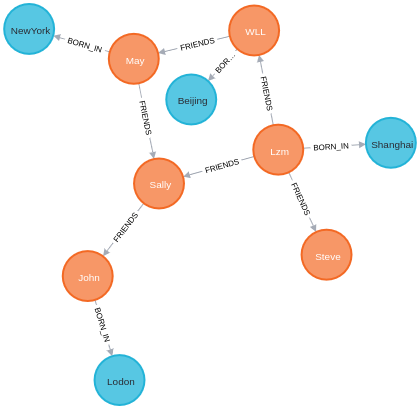
python操作:py2neo模块
py2neo模块:通过操作python变量,达到操作neo4j的目的。
简单示例代码:
1 | # step 1:导包 |
通过csv文件批量导入图数据
参考链接:Neo4j批量导入数据的几种方式
