基于医疗知识图谱的问答系统
1 简介
一个以疾病为中心的一定规模医药领域知识图谱,并以该知识图谱完成自动问答与分析服务。
此项目立足医药领域,以39健康网为数据来源,以疾病为核心,构建起一个包含7类规模约为3.7万的知识实体,6类规模约21万的实体关系的知识图谱。基于上述的知识图谱进行自动问答。
垂直型网站(Vertical website):注意力集中在某些特定的领域或某种特定的需求,提供有关这个领域或需求的全部深度信息和相关服务。
2 运行环境及方式
运行环境
- python3.0及以上
- neo4j 3.5.0及以上
- jdk 1.8.0 (需要jre)
运行方式
- 配置好neo4j数据库(作为存储)和相应的python 依赖包(py2neo)。修改neo4j数据库用户名密码。
- 知识图谱导入:
python build_graph.py(数据很多,所以时间在2个小时左右或者更长。注意:有些数据和模型的路径需要修改。) - 启动问答:
python kbqa_test.py(需要pip不少的模块)
ubuntu安装py2neo:
pip install py2neo
3 系统的医疗知识图谱
a. 知识图谱架构:
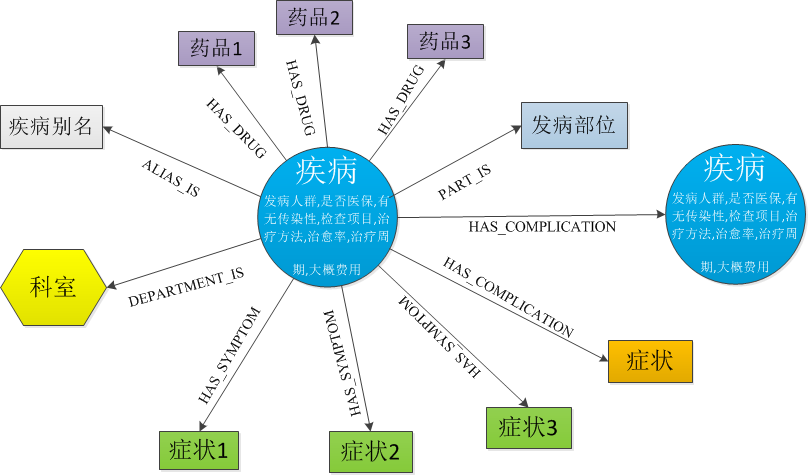
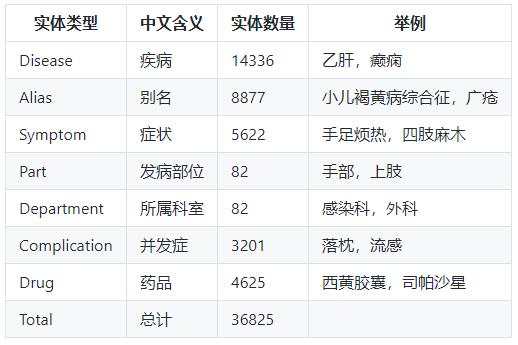
b. 知识图谱中的实体类型
通过运行项目,Department(科室)这一实体的图为:  (其余省略)
(其余省略)
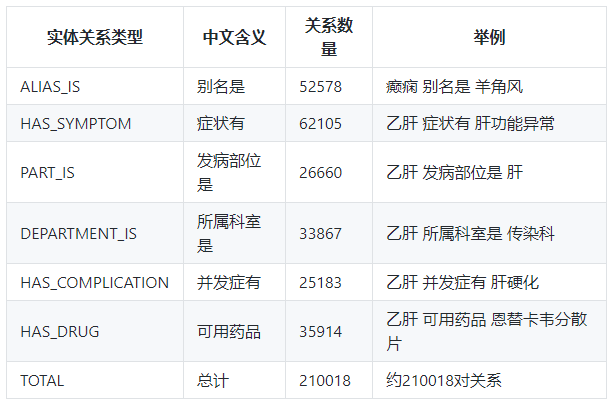
c. 知识图谱实体关系类型
通过运行项目,HAS_SYMPTOM(症状有)这一实体关系的图为: 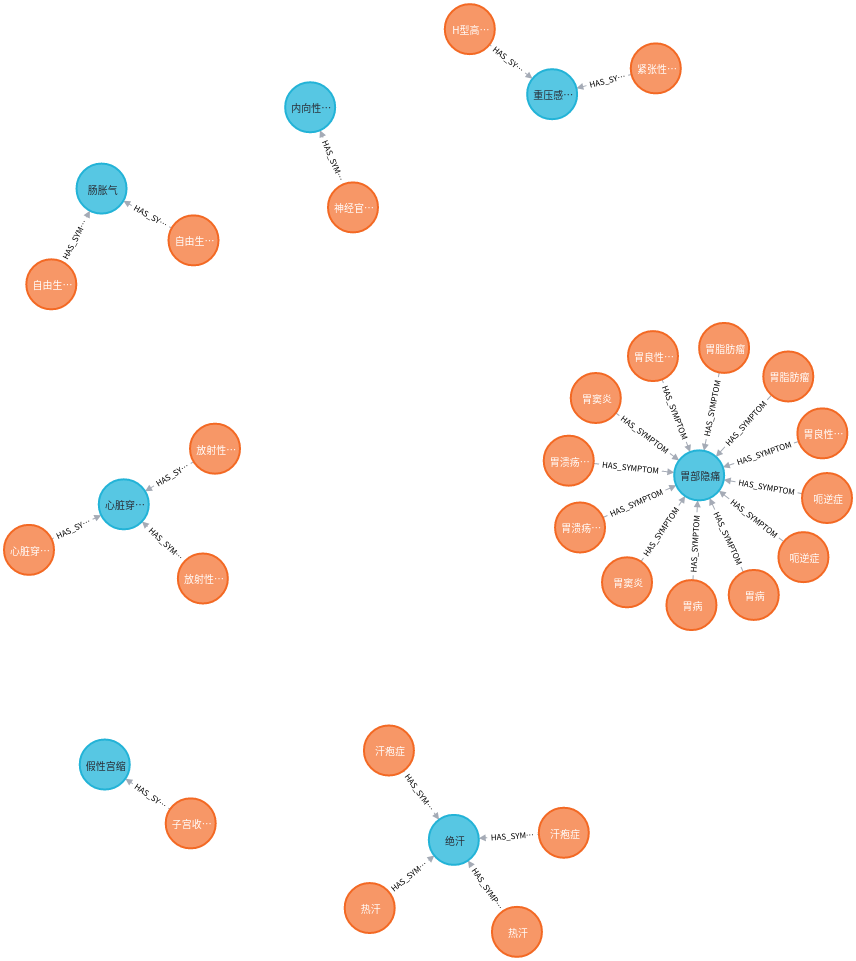 (其余省略)
(其余省略)
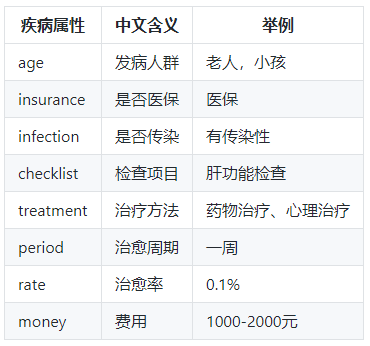
d. 知识图谱中的疾病属性
4 系统的问题意图识别
识别用户查询意图利用特征词分类的方法,采用朴素贝叶斯(Naive Bayes)算法训练得到意图分类模型。
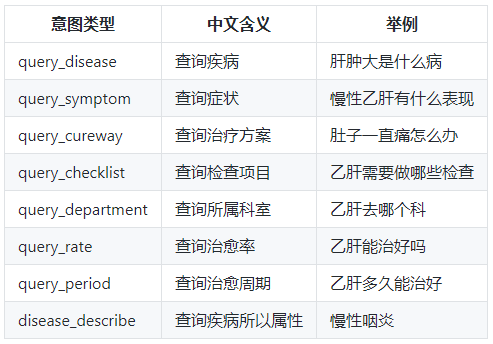
意图类别比较少,项目的分类模型只能预测出上面设定的7类意图。对于问题句子中有多个意图的情况只能预测出一类。
5 问答测试
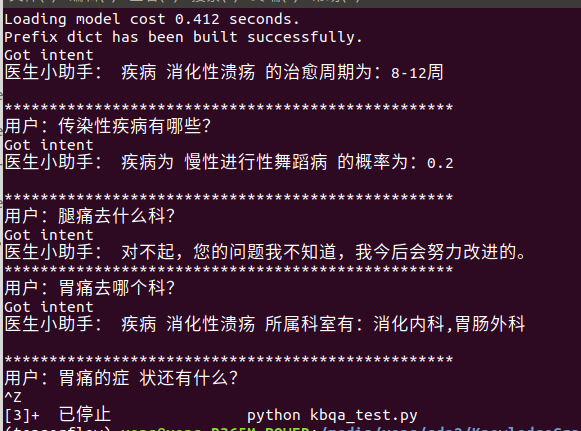
从图里能明显看出来,现在程序问题回答的不尽人意,遇到有些问题意图识别和答案查找很慢。知识图谱还比较小,对于许多问题都检索不出答案。
程序也只能进行单轮对话。