医疗问答系统详解一
医疗问答系统介绍:博客
这部分是学习如何将用户在问答系统中的输入(自然语言)转化成知识库的查询语句。
知识库问答
知识库问答(Knowledge Base Question Answering, KBQA):给定自然语言问题,通过对问题进行语义理解和解析,进而利用知识库进行查询、推理得出答案。 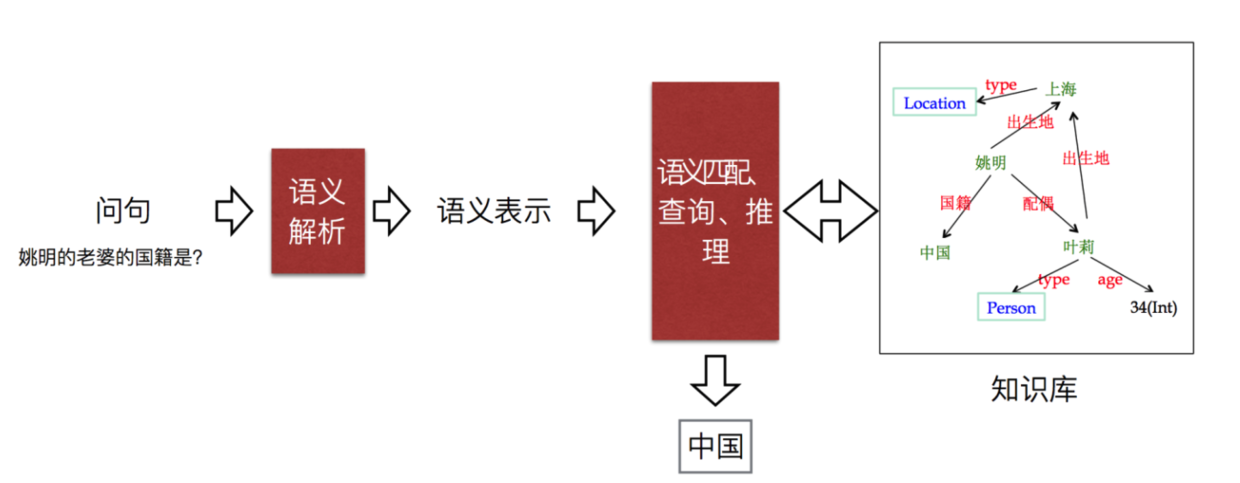
医疗问答系统的意图识别
用户的问题通过命名实体模块可以将问题中的相关实体获取到,接着根据问题中包含的实体进行意图识别。 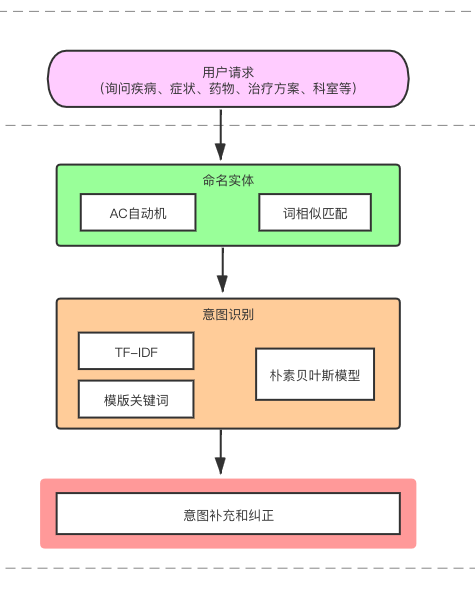
相应的主体类EntityExtractor框架如下:
1 | class EntityExtractor: |
命名实体模块
- 整体思路
- 对于用户的输入,先使用预先构建的疾病、疾病别名、并发症和症状的AC Tree进行匹配。
- 如果所有AC Tree树都无法匹配到实体,则使用
jieba中的分词库对用户输入的文本进行切分,将每一个词都与疾病词库、疾病别名词库、并发症词库和症状词库中的词计算相似度得分(overlap score,余弦相似度分数,编辑距离分数)。如果相似度得分超过0.7,则认为该词是这一类实体。 - 最后排序选取最相关的词作为实体。
项目的所有实体类型共有7类Disease,Alias,Symptom,Part,Department,Complication,Drug,但实体识别时仅使用了Disease,Alias,Complication,Symptom。
- 项目相关代码
1 构建AC Tree
1 | import ahocorasick |
函数调用模块:
1 | def __init__(self): |
2 使用AC Tree进行问句过滤(实体匹配)
1 | ##模式匹配,得到匹配的词和类型。 |
函数调用模块:
1 | def extractor(self, question): |
3 利用相似度进行的实体匹配
当没有通过AC Tree匹配到实体时,使用查找相似词的方式进行实体匹配。
1 | import re |
意图识别模块
- 整体思路
- 利用TF-IDF表征文本特征,同时构建一些人工特征(每一类意图常见词在句子中出现的个数)。
- 训练朴素贝叶斯模型进行意图识别任务。
- 使用实体信息进行意图的纠正和补充。
- 项目相关代码
1 特征构建
关于TF-IDF:我的博客
TF-IDF特征:
1 | ## 提取问题的TF-IDF特征 |
人工特征:
1 | self.symptom_qwds = ['什么症状', '哪些症状', '症状有哪些', '症状是什么', '什么表征', '哪些表征', '表征是什么', |
2 使用训练好的朴素贝叶斯模型进行文本分类
1 | # 意图分类模型文件 |
3 根据所识别的实体进行补充和纠正意图
1 | # 已知疾病,查询症状 |
参考链接:链接1
参考链接:链接2