天池文本分类实践
这次的实践依托天池的中文预训练模型泛化能力挑战赛,完成数据集OCNLI、OCEMOTION、TNEWS上的任务。
0 文本分类任务简介
0.1 数据集
数据集说明
- OCNLI:是第一个非翻译的、使用原生汉语的大型中文自然语言推理数据集;
- OCEMOTION:是包含7个分类的细粒度情感性分析数据集;
- TNEWS:来源于今日头条的新闻版块,共包含15个类别的新闻;
0.2 任务简介
任务及数据格式说明
- 任务1: \(\color{purple}{OCNLI--中文原版自然语言推理}\)
数据格式:
id 句子1 句子2 标签
1 | 0 一月份跟二月份肯定有一个月份有. 肯定有一个月份有 0 |
- 任务2: \(\color{purlpe}{OCEMOTION--中文情感分类}\)
数据格式:
id 句子 标签
1 | 0 你知道多伦多附近有什么吗?哈哈有破布耶...真的书上写的你听哦...你家那块破布是世界上最大的破布,哈哈,骗你的啦它是说尼加拉瓜瀑布是世界上最大的瀑布啦...哈哈哈''爸爸,她的头发耶!我们大扫除椅子都要翻上来我看到木头缝里有头发...一定是xx以前夹到的,你说是不是?[生病] sadness |
- 任务3:\(\color{purple}{TNEWS--今日头条新闻标题分类}\)
数据格式:
id 句子 标签
1 | 0 上课时学生手机响个不停,老师一怒之下把手机摔了,家长拿发票让老师赔,大家怎么看待这种事? 108 |
数据下载
- 训练集
| 名称 | 大小 | Link |
|---|---|---|
| OCNLI_train1128.csv | 5.78MB | 链接 |
| TNEWS_train1128.csv | 4.38MB | 链接 |
| OCEMOTION_train1128.csv | 4.96MB | 链接 |
- 测试集
| 名称 | 大小 | Link |
|---|---|---|
| ocnli_test_B.csv | 166KB | 链接 |
| tnews_test_B.csv | 102KB | 链接 |
| ocemotion_test_B.csv | 302KB | 链接 |
1 baseline
\(\color{purple}{自己的环境配置}\):
系统:Ubuntu18.04, GPU:1080 Ti
pytorch:1.7.1(根据自己的cuda版本下载,下载官网:传送门)

cuda是11.1的话,下载11.0的pytorch亲测可用。
- python依赖包:
transformers和sklearn:
1 | pip install transformers |
1 | pip install sklearn |
- docker
ubuntu下安装docker:
首先apt更新: 1
sudo apt-get update
1
sudo apt install docker.io
1
docker info
1.1 baseline简介
该baseline利用预训练的BERT模型生成embedding,然后各个任务有自己的分类层(各自的全连接层)。 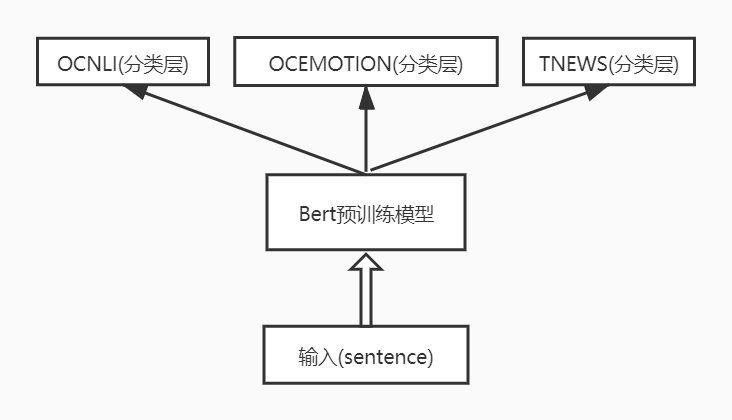
1.2关于数据的处理
该baseline利用generate.py程序完成了:原始训练集划分出了3000条数据作为验证集(dev.csv)。
数据处理时出现的问题:UnicodeDecodeError: 'gbk' codec can't decode byte 0xaf in position 6: illega
解决方法:打开(含有中文)文件时open函数的参数里面加入:encoding=utf-8。修改后示例:with open('./tianchi_datasets/' + e + '/total.csv', encoding='utf-8') as f:
1.3 训练和推理
训练模型,5个epoch(
train.py中默认20个epoch,运行太久,先改小一点尝试):程序会自动保存验证集上平均f1分数最高的模型到./saved_best.pt.1
python ./train.py
用训练好的模型
./saved_best.pt生成结果:1
python ./inference.py
打包预测结果。进入到
submission文件夹下执行:这样就将生成的三个任务的预测结果打包到1
zip -m ./result.zip *.json
result.zip中了。
1.4 提交
生成Docker并进行提交,参考:https://tianchi.aliyun.com/competition/entrance/231759/tab/174
- 创建云端镜像仓库:https://cr.console.aliyun.com/
- 创建命名空间和镜像仓库;
- 切换到submission文件夹下:
- 先登录。用于登录的用户名为阿里云账号全名,密码为开通镜像服务时设置的密码。Ubuntu下登录命令:
1
sudo docker login lzm_belief registry.cn-shenzhen.aliyuncs.com
- 再创建。使用本地Dockefile进行构建,使用自己创建的镜像仓库的公网地址
1
sudo docker build -t registry.cn-shenzhen.aliyuncs.com/nlp_lzm/nlp_task:1.0 .
- 提交镜像到云端
1
sudo docker push registry.cn-shenzhen.aliyuncs.com/nlp_lzm/nlp_task:1.0
- 提交运行结果时要填的信息:

- 先登录。用于登录的用户名为阿里云账号全名,密码为开通镜像服务时设置的密码。Ubuntu下登录命令:
2 改进baseline
原baseline使用的预训练模型为bert-base,模型描述如下:
| 网络层数 | 隐藏层维度 | Attention的多头数 |
|---|---|---|
| Layer = 12 | Hidden = 768 | Heads = 12 |
修改为利用ernie1.0(chinese)预训练模型,该模型与上面bert-base的Layer、Hidden、Heads一致。
下载预训练模型的参数
下载ernie1.0预训练参数:链接here。(参考链接传送门)
将其中的三个文件所在文件夹修改为ernie_pretrain_model,将其放到项目文件夹下。
修改baseline中的train.py文件中的if __name__ == '__main__'语句下面的pretrained_model和tokenizer_model为./ernie_pretrain_model。